
どうも、とがみんです。
以前の記事で教師あり学習と教師なし学習について紹介ました。

この記事では、機械学習の主な手法である「分類」、「回帰」、「クラスたらリング」、「次元削減」について紹介していきます。
機械学習における分析手法の分類
以下の図は「scikit-learn」のアルゴリズムのチートシートで、機械学習に関するデータの分析手法の選定に利用します。
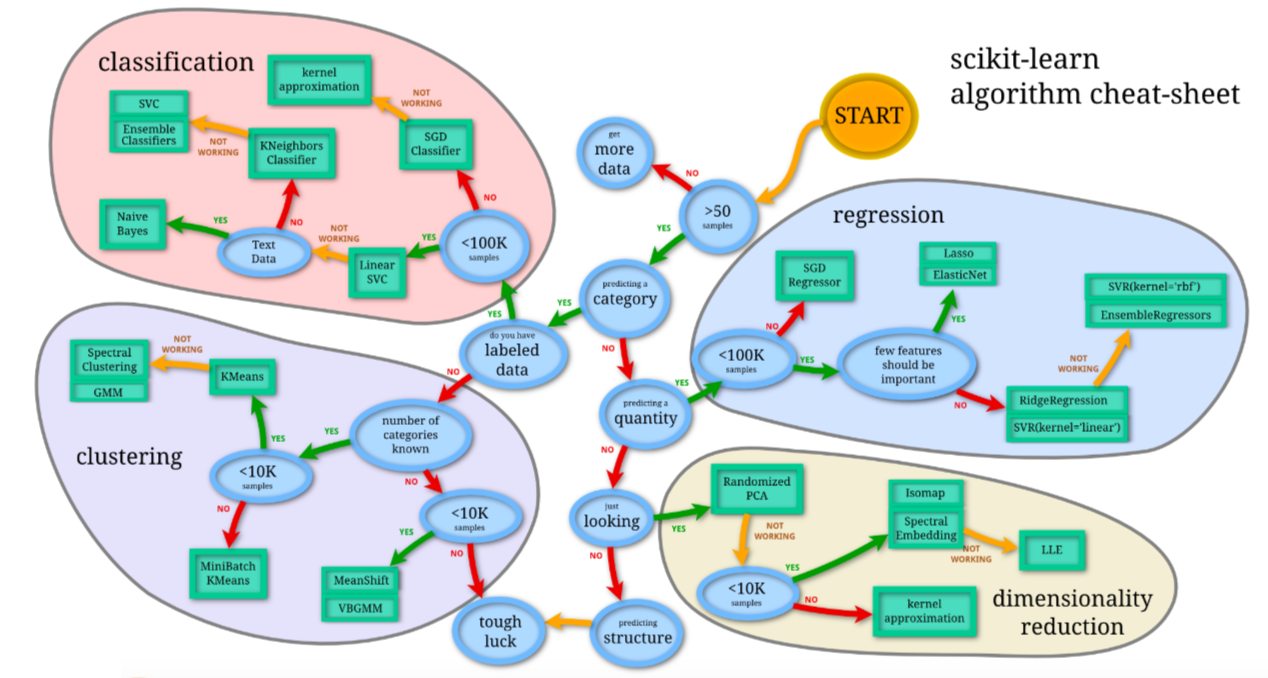
上図を見てもわかる通り、データの分析の手法には、
- 分類:classification
- 回帰:regression
- クラスタリング:clustering
- 次元削減:dimensionality redution
の4つに分けられます。
それぞれについて紹介していきます。
分類
「分類」はデータをそれぞれのカテゴリに分類するもので、機械学習の手法の代表的な使い道の一つです。
データが以下の赤線よりも右側にきたらオレンジグループ、左側にきたらブルーグループといった感じに分類します。
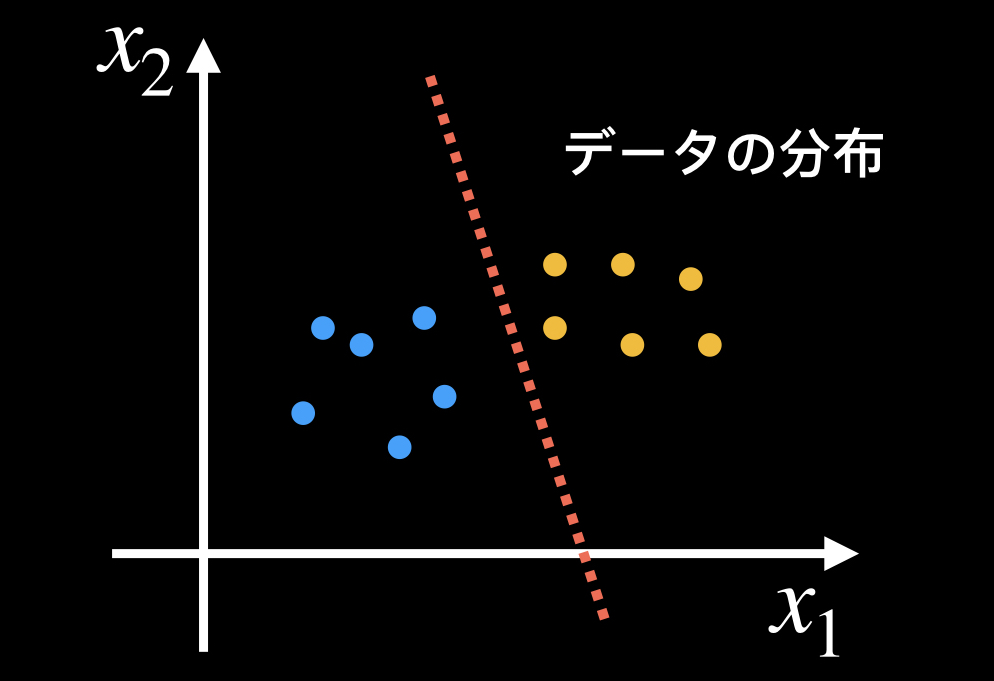
メールをスパムと非スパムに分類したり、顧客の購買情報から、買うか買わないかを予測するといった2値分類や、
ある記事があったとして、それが経済についてなのか、政治についてなのか、スポーツ、ITについてなのか、いづれのジャンルに属するかを判定するといった多値分類があります。
回帰分析
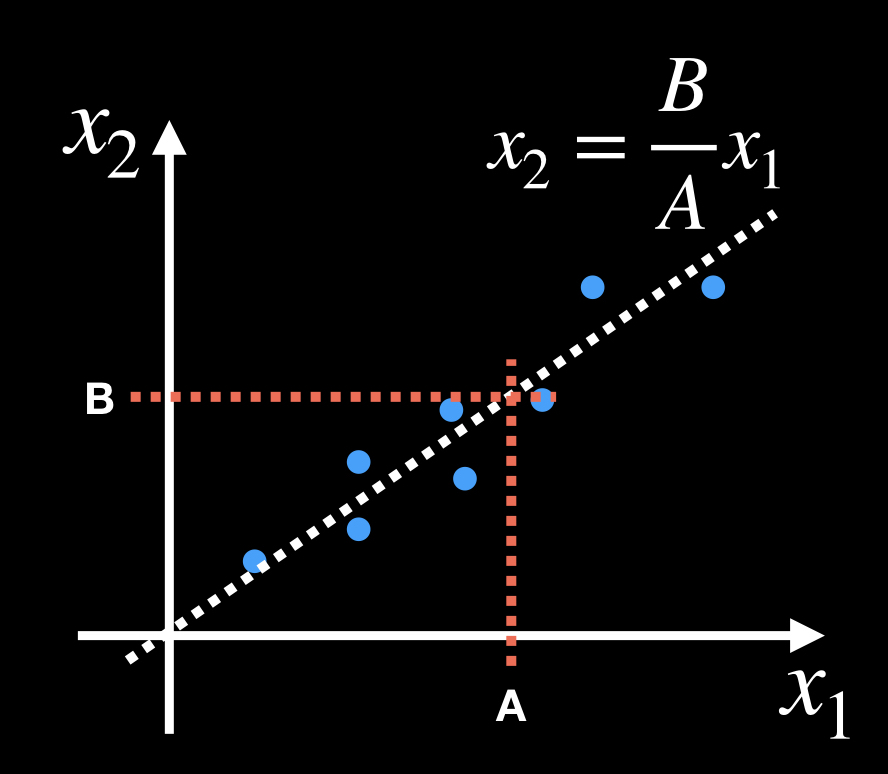
過去のデータを元に、そのデータに当てはまる関数を予測し、未知のデータに対する予測を行う分析手法です。
以下の図で、過去のデータから未知のデータx1=Aに対して、x2=Bであるという予測ができます。
クラスタリング(クラスタ分析)
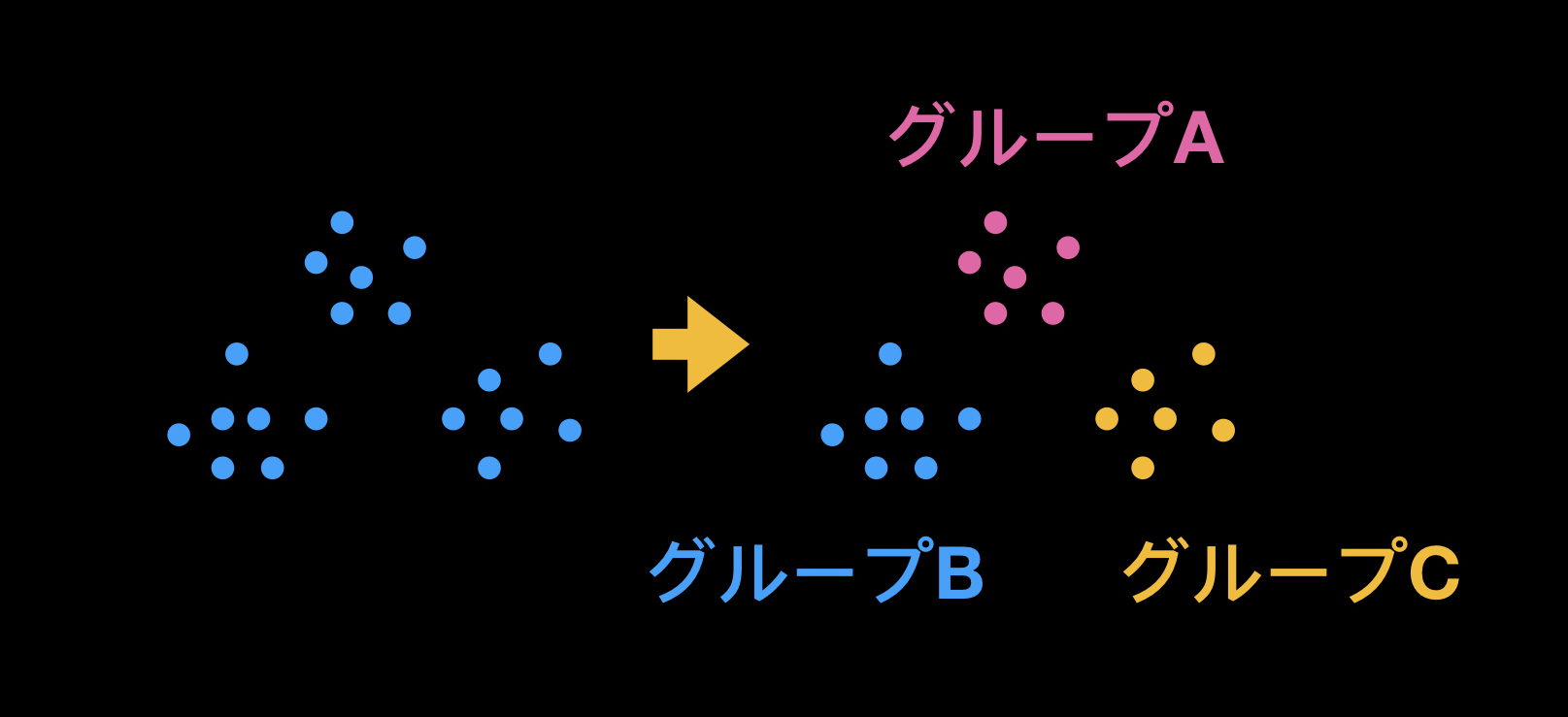
「クラスタリング」は、教師なし学習の一つで、対象とするデータの集合を、機能やカテゴリごとに分けて集め、部分的な集合に分割することです。
分割後の各部分集合はクラスタと呼ばれます。
1つのクラスタ内のデータは同質となり、かつそれぞれのクラスタが異質になるように分類することが、この手法の目的です。
数千もの色が使われた画像を10色だけで、印刷しないといけないとなった場合に、色の近さから10つに分類したり、
マーケティング施策を展開していくにあたって、そのターゲットを顧客、性別、年齢、趣味といった属性に基づいてグループ化し、それぞれに適したマーケティング施策を考えたりする際にこの分析手法を利用したりします。
クラスタリングの手法には、似たデータ同士をまとめていくことで、クラスターを形成していく階層的手法と、似たデータ同士が同じクラスターになるよう全体を分割していく非階層的手法に分けられます。
次元削減
次元削減とは、データの持つ情報をできる限り損なわずに、より少ない指標にようやくするための手法です。
次元を削減することにより、データの特徴を用意に視覚化することができます。
主に、多次元のデータに対して行われます。
以下は4次元のIrisデータを3次元と2次元に次元圧縮し、視覚化したものです。

まとめ
機械学習におけるよるデータ分析手法の種類について紹介しました。
参考文献













