
どうも、とがみんです。
以前の記事で、TensorFlowを利用してプログラムを書く流れについて紹介しました。

この記事では、TensorFlowを利用して、ニューラルネットワークを構築し、手書き画像データを分類するシステムを作成していきます。
Contents
今回実装するものの概要
今回は、以下のような単純なニューラルネットワークを「TensorFlow」を利用して構築します。
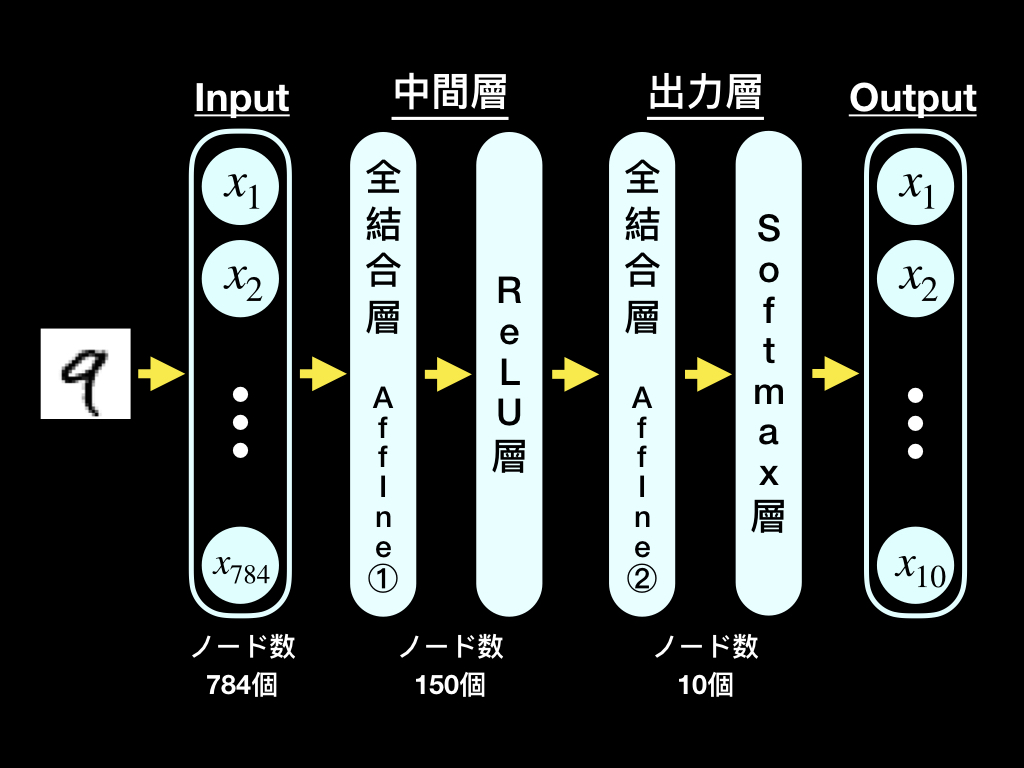
手書き数字画像データの準備
手書き数字画像データの準備をしていきます。
1 2 3 4 5 | import tensorflow as tf #手書き数字画像データの取得 mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() |
それぞれのデータの形状を確認すると以下のような感じになってます。

画像データは縦×横=28ピクセル×28ピクセルで、学習用画像60000個、テスト用10000個あります。
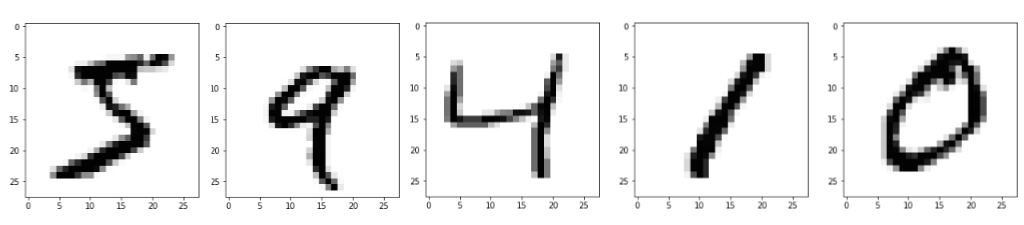
データの前処理として、以下2つの処理を行います。
- 画像データを[28×28]の2次元データから、[1×748]の一次元データへ変換し、「0〜255」の値を「0〜1」へ変換
- 正解データを「1〜9」の数字ではなく、「one-hot表現」へ変換。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #①----------------------------------------- x_train2 = [] x_test2 = [] #学習用画像データ for i in range(train_size): x_train2.append(x_train[i].reshape(-1,)) #テスト用画像データ for i in range(test_size): x_test2.append(x_test[i].reshape(-1,)) x_train = np.array(x_train2)/255 x_test = np.array(x_test2)/255 #②----------------------------------------- n_labels = len(np.unique(y_train)) y_train = np.eye(n_labels)[y_train] n_labels = len(np.unique(y_test)) y_test = np.eye(n_labels)[y_test] |
データの形状は以下のように変換されます。

手書き数字画像データ分類ニューラルネットワークの実装
以下のステップで、ニューラルネットワークのプログラムを書いていきます。
- パラメータの準備
- 処理内容の定義
- 処理の実行プログラムの作成
パラメータの準備
入力データ、正解データを入れるようのプレースホルダーの準備と、各パラメータの初期化を行います。
1 2 3 4 5 6 7 8 9 10 | #画像データを入れる用のプレースホルダー x = tf.placeholder(tf.float32, [None, 784]) #正解データを入れる用のプレースホルダー y = tf.placeholder(tf.float32, [None, 10]) #各パラメータの初期化 w1 = tf.Variable(tf.truncated_normal(shape = [784,150],stddev = 0.01)) b1 = tf.Variable(tf.truncated_normal(shape = [150],stddev = 0.01)) w2 = tf.Variable(tf.truncated_normal(shape = [150,10],stddev = 0.01)) b2 = tf.Variable(tf.truncated_normal(shape = [10],stddev = 0.01)) |
プレースホルダー内の配列の型にNoneを指定しておくと、入力データのサイズが変わっても対応することができます。
truncated_normalは、ランダムな値を用意してくれます。
>Tensorflow API: tf.truncated_normal
処理内容の定義
各レイヤーの処理を記述します。
1 2 3 4 5 6 7 8 9 10 11 | #Affine1層 a1 = tf.matmul(x,w1)+b1 #ReLU層 z1 = tf.nn.relu(a1) #Affine2層 a2 = tf.matmul(z1,w2)+b2 #Softmax層 out = tf.nn.softmax(a2) |
誤差関数、パラメータを最適化させる際に利用する関数、学習させる関数を記述します。
1 2 3 4 5 6 7 8 | #誤差関数:クロスエントロピー関数 cross_entropy = -tf.reduce_sum(y*tf.log(out)) #パラメータ最適化関数:Adam optimizer = tf.train.AdamOptimizer(learning_rate = 0.01) #学習 train = optimizer.minimize(cross_entropy, var_list=[w1,b1,w2,b2]) |
学習させるパラメータをvar_listに指定します。
認識精度を確認するための関数を記述します。
1 2 3 | #認識精度 correct_prediction = tf.equal(tf.argmax(out,1), tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) |
correct_predictionには、出力結果と正解データが同じであれば、True、異なれば、Falseを返します。
tf.castで、Bool型のデータを少数型に変換し、その平均をtf.reduce_meanで取ることによって、認識精度を計算しています。
処理の実行プログラムの作成
処理を実行するプログラムを書いていきます。値を保持しておくための配列を用意しておきます。
1 2 3 4 5 6 | #各値を格納するための配列 accuracyListL = []#学習用データにおける認識精度 accuracyListT = []#テスト用データにおける認識精度 lossListL = []#学習用データにおける損失値 lossListT = []#テストデータにおける損失値 params = {}#学習後のパラメータの値を保存する辞書型配列 |
以下のコードを実行させると学習が始まります。
学習はバッチサイズを100とし、600回バッチ学習を行います。1エポック分の学習をさせています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | with tf.Session() as sess: sess.run(tf.initialize_all_variables())#変数の初期化 #バッチサイズの指定 batch_size = 100 for i in range(600): #トレーニングデータからランダムにバッチサイズ分のデータを取得。 batch_mask = np.random.choice(train_size,batch_size) x_batch = x_train[batch_mask] y_batch = y_train[batch_mask] #学習 sess.run(train,feed_dict = {x:x_batch,y:y_batch}) #10バッチ毎に、認識精度と損失の平均値を配列にん格納。 if i % 10 == 0: #学習させたデータの認識精度 resultL = sess.run(accuracy,feed_dict = {x:x_batch,y:y_batch}) #テストデータを用いて認識精度の計算 resultT = sess.run(accuracy,feed_dict = {x:x_test,y:y_test}) #学習データの損失の平均値 resultL2 = sess.run(cross_entropy,feed_dict = {x:x_batch,y:y_batch})/batch_size #テストデータの損失の平均値 resultT2 = sess.run(cross_entropy,feed_dict = {x:x_test,y:y_test})/test_size #認識精度の推移 accuracyListL.append(resultL) accuracyListT.append(resultT) #損失値の推移 lossListL.append(resultL2) lossListT.append(resultT2) print('バッチ数:',i,'認識精度(学習)',resultL,'認識精度(テスト)',resultT,'損失値(学習)',resultL2,'損失値(テスト)',resultT2) #学習終了後の各パラメータの取得 params['w1'] = sess.run(w1) params['b1'] = sess.run(b1) params['w2'] = sess.run(w2) params['b2'] = sess.run(b2) |
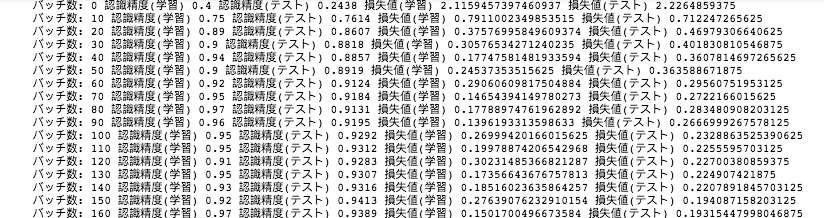
10バッチ毎の以下の値をそれぞれ出力してくれます。
- 学習データに対する認識精度
- テストデータに対する認識精度
- 学習データの損失値
- テストデータの損失値
学習結果
最後に学習の結果を表示します。
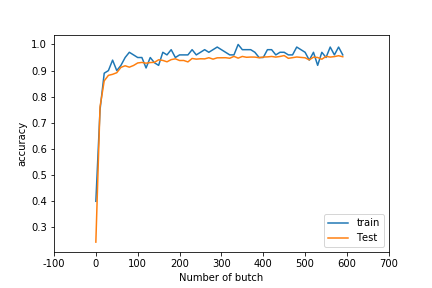
認識精度の推移
以下のコードで認識精度に関するグラフを表示します。
1 2 3 4 5 6 7 8 9 | #認識精度のグラフ plt.plot(accuracyListL) plt.plot(accuracyListT) xticks, strs= plt.xticks() plt.xticks(xticks,["%d" % x for x in 10*xticks]) plt.ylabel('accuracy') plt.xlabel('Number of butch') plt.legend(['train','Test'], loc='lower right') plt.show() |
青は、学習用データに対する認識精度、オレンジはテストデータに対する認識精度についてです。
テストデータに対する最終的な認識精度は「95.29%」になりました。
損失関数の値の推移
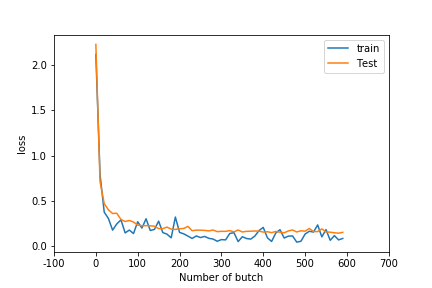
以下のコードで、損失関数の値に関するグラフを表示します。
1 2 3 4 5 6 7 8 9 10 | #損失関数の値のグラフ plt.plot(lossListL) plt.plot(lossListT) xticks, strs= plt.xticks() plt.xticks(xticks,["%d" % x for x in 10*xticks]) plt.ylabel('loss') plt.xlabel('Number of butch') plt.legend(['train','Test'], loc='lower right') plt.savefig('images/TensorNNloss') plt.show() |
青は、学習用データに対する損失関数の値、オレンジはテストデータに対する損失関数の値についてです。
テストデータに対する最終的な損失値は「0.1531」になりました。
まとめ
TensorFlowを利用して、ニューラルネットワークを実装し、手書き文字の画像データの分類を行いました。
参考文献
>Get Started with TensorFlow|TensorFlow
>TensorFlowで全結合ニューラルネットを実装+重みを取得する












