
どうも、とがみんです。
以前の記事で、自己符号化器(Auto encoder:オートエンコーダー)について紹介しました。

この記事では、TensorFlowを用いて自己符号化器を実装し、手書き数字画像データの次元圧縮と、その復元について紹介していきます。
Contents
実装する自己符号化器(オートエンコーダ)の概要
今回実装するのは、以下のようなモデルです。
中間層のノードは400(20×20)、100(10×10)、25(5×5)とし、それぞれの次元圧縮後の出力結果と復元結果を比較していきます。
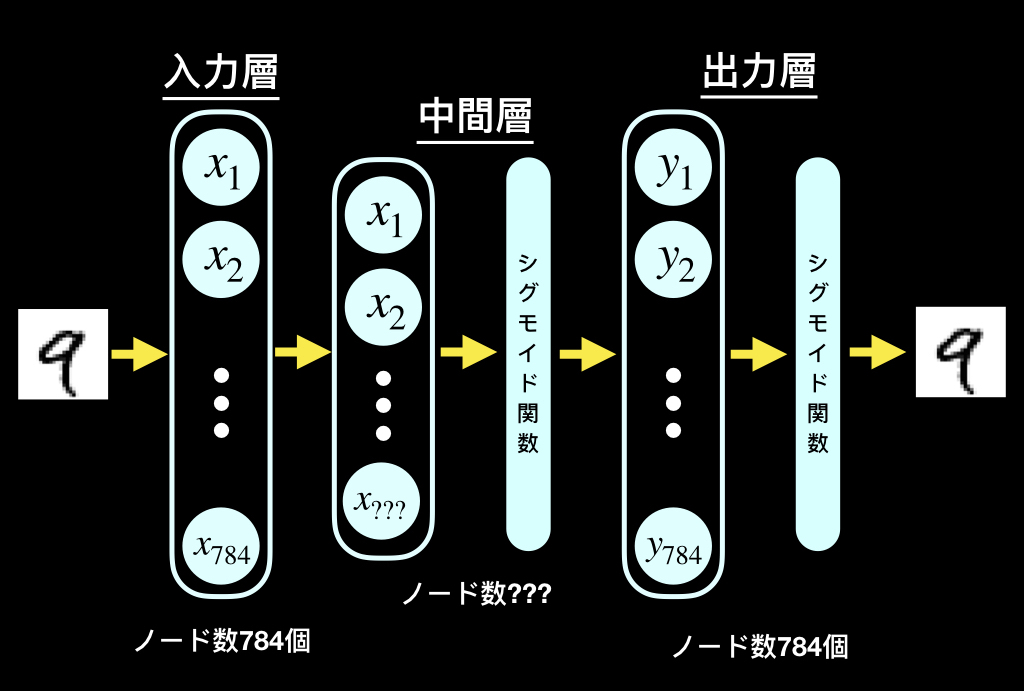
活性化関数にはシグモイド関数を利用します(出力を0〜1の間にするため)。
データの準備
手書き数字の画像データを準備します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() #データのサイズ train_size = x_train.shape[0] test_size = x_test.shape[0] #①[28×28]のデータを[1×784]へ--------------- x_train2 = [] x_test2 = [] #学習用画像データ for i in range(train_size): x_train2.append(x_train[i].reshape(-1,)) #テスト用画像データ for i in range(test_size): x_test2.append(x_test[i].reshape(-1,)) #「0〜255」の値を「0〜1」に変換 x_train = np.array(x_train2)/255 x_test = np.array(x_test2)/255 |

自己符号化器(オートエンコーダ)の実装
以下のステップで実装していきます。
- パラメータの準備
- 処理内容の定義
- 処理の実行プログラムの作成・実行後の保存
- 学習後モデルの読み込み
パラメータの準備
各パラメータを入れる変数を用意します。デコード用の重みパラメータはエンコード時の重みパラメータを転置したものになっています。
1 2 3 4 5 6 7 8 9 10 11 | #画像データを入れる用のプレースホルダー x = tf.placeholder(tf.float32, [None, 784]) #圧縮後の次元数(中間層のノード数) dim = 100 #各パラメータの初期化 w_enc = tf.Variable(tf.truncated_normal(shape = [784,dim],stddev = 0.01)) b_enc = tf.Variable(tf.truncated_normal(shape = [dim],stddev = 0.01)) w_dec = tf.transpose(w_enc) b_dec = tf.Variable(tf.truncated_normal(shape = [784],stddev = 0.01)) |
処理内容の定義
エンコード処理、デコード処理を以下のように定義します。
1 2 3 4 5 | #エンコード後の結果 encoded = tf.sigmoid(tf.matmul(x,w_enc)+b_enc) #デコード後の結果 decoded = tf.sigmoid(tf.matmul(encoded,w_dec) + b_dec) |
学習について、損失関数には、2乗和誤差、学習アルゴリズムは「急速降下法」を使用します。
1 2 3 4 5 6 7 8 | #誤差関数:2乗和誤差 loss = tf.nn.l2_loss(decoded - x) #学習アルゴリズム optimizer = tf.train.GradientDescentOptimizer(0.005) #学習 train = optimizer.minimize(loss, var_list=[w_enc,b_enc,b_dec]) |
処理の実行プログラムの作成
学習後パラメータ保存用のオブジェクトと、損失関数の値の推移を格納するリストを用意します。
1 2 3 4 5 6 | #パラメータ保存用オブジェクト saver = tf.train.Saver() savePlace = 'middle400/middle400' #損失関数の値の推移を格納するためのリスト lossList = [] |
実行プログラムを記述していきます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | with tf.Session() as sess: sess.run(tf.initialize_all_variables())#変数の初期化 #バッチサイズ batch_size = 100 for i in range(6000): batch_mask = np.random.choice(train_size,batch_size) x_batch = x_train[batch_mask] sess.run(train, feed_dict={x: x_batch}) lossValue = sess.run(loss,feed_dict={x: x_batch})/batch_size if i % 100 == 0: print("バッチ数:",i,"loss:",lossValue) #パラメータの保存 saver.save(sess, 'model/autoencoder/'+savePlace) |
学習後モデルの読み込み
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | encodedList = []#エンコード後の画像データを入れる。 decodedList = []#デコードした画像のデータリスト imgNum = 5#表示数 with tf.Session() as sess: # 訓練済みモデルのmetaファイルを読み込み saver = tf.train.import_meta_graph('model/autoencoder/'+ savePlace + '.meta') saver.restore(sess, 'model/autoencoder/' + savePlace) for i in x_train[:imgNum]: encodedImgData = sess.run(encoded,feed_dict={x:i.reshape(1,-1)}) encodedList.append(encodedImgData) decodeImgData = sess.run(decoded,feed_dict={x:i.reshape(1,-1)}) decodedList.append(decodeImgData) |
結果の出力
得られた結果を表示します。まず、表示するために、データを整えます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #リストをnp.array型へ変換 encodedList = np.array(encodedList) decodedList = np.array(decodedList) encodedList2 = [] decodedList2 = [] #データの形式を「1×〜」から、「x×x」に変換。 for i in range(imgNum): encodedImg = encodedList[i].reshape(length,length) encodedList2.append(encodedImg) decodedImg = decodedList[i].reshape(28,28) decodedList2.append(decodedImg) |
以下のコードによって、結果を出力します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #表示枚数 col = 5 #1行に表示する数 row = int(imgNum/col)#行数 #学習用画像(元画像) plt.figure(figsize = (21,21)) plt.subplots_adjust(wspace=0.3, hspace= 0.3) for i in range(imgNum): plt.subplot(row+1, col, i+1) img = x_train[i].reshape(28,28) plt.imshow(img,cmap='Greys') plt.show() #エンコード後データ plt.figure(figsize = (21,21)) plt.subplots_adjust(wspace=0.3, hspace= 0.3) for i in range(imgNum): plt.subplot(row+1, col, i+1) img = encodedList2[i] plt.imshow(img,cmap='Greys') plt.show() #デコード後の画像 plt.figure(figsize = (21,21)) plt.subplots_adjust(wspace=0.3, hspace= 0.3) for i in range(imgNum): plt.subplot(row+1, col, i+1) img = decodedList2[i] plt.imshow(img,cmap='Greys') plt.show() |
以下に中間ノード数、400(20×20)、100(10×10)、25(5×5)のそれぞれに置いて、エンコード後(次元圧縮後)結果とその復元結果について書いていきます。
中間ノード数400(20×20)
上から、「元画像データ」、「エンコード後(次元圧縮後)画像データ」、「復元後画像データ」になります。

中間ノード数100(10×10)
上から、「元画像データ」、「エンコード後(次元圧縮後)画像データ」、「復元後画像データ」になります。

中間ノード数25(5×5)
上から、「元画像データ」、「エンコード後(次元圧縮後)画像データ」、「復元後画像データ」になります。

参考文献
>Autoencoder / Sparse Autoencoderの実装と実験
>Tensorflow オートエンコーダでmnistを学習(Qiita記事を見ながら..)













