
どうも、AWS勉強中のとがみんです。
マイクロサービス間のデータ連携を行う上で、Amazon Kinesis Data Streamも選択肢の一つとなりうるので、このサービスについて簡単に調べて、まずは動作確認を行なってみることにしました。
この記事では調べたことと実際に動作を確認する所までを整理していきます。
Contents
Amazon Kinesis Data Streamsとは?
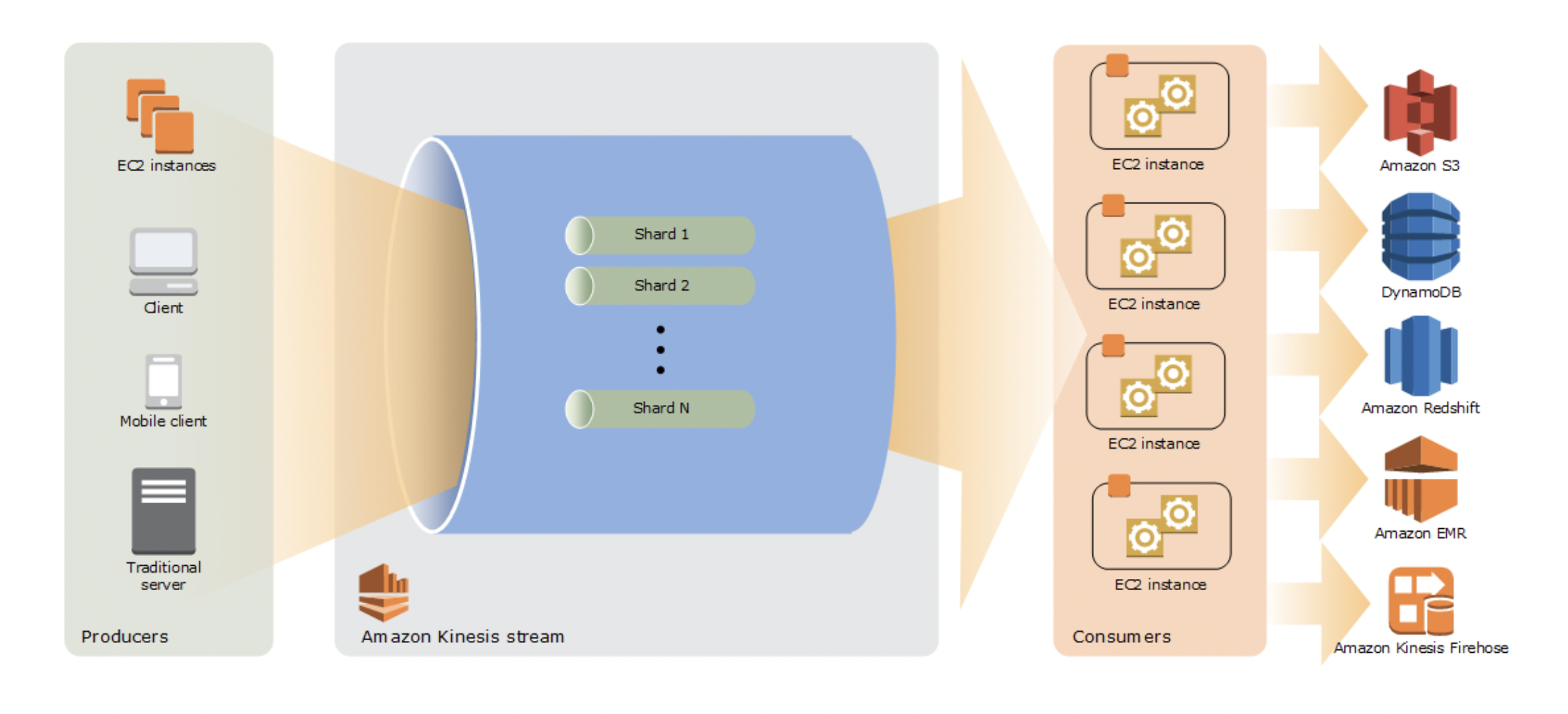
Amazon Kinesis Data Streamとは、ストリームデータを取り込んで保存し、様々な転送先へ転送するサービスです。
センサーやコンピューター等から、次から次へと送られてくるデータを受け取り、S3やDynamoDBなど、AWSの他のサービスへ高速に転送します。
Amazon Kinesis Data Streamは、データの種類や処理の用途に応じて「ストリーム」を作成し、ストリームは1つ以上の「シャード」で構成されます。
「シャード」は、Amazon Kinesisストリームにおけるスループットの基本単位で、通信量と要求されるスループットによってシャード数を決定します。
またオンデマンドモードに設定しておくと、データ規模に合わせて動的にスケーリングするため、リアルタイム性を損なわないという特徴があります。
スループット:単位時間あたりに処理できるデータ量
参考:Amazon Kinesis Data Streams の用語と概念
今回作成するもの
今回は、Amazon Kinesis Data Streamがストリーミングデータを受信すると、AWS Lamdaが起動されCloud Watchにそのログが出力されるようなものを作成します。
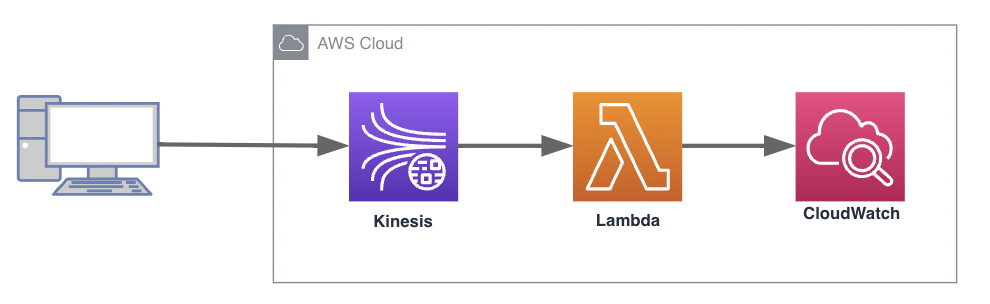
作業手順概要
- Amazon Kinesis Data Streamを作成する
- Lambdaへ付与するIAMロールの作成
- Kinesis Data Streamのデータを処理するLamdaの作成
- 動作確認
作業手順詳細
Amazon Kinesis Data Streamを作成する
AWSマネジメントコンソールから、Amazon Kinesis Data Streamを作成します。
データストリーム名
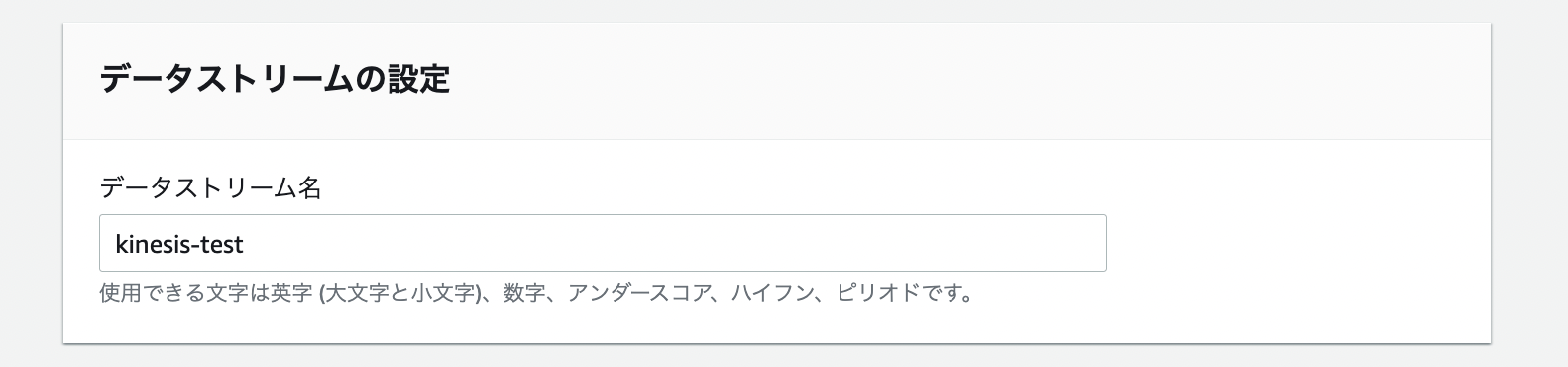
今回は「kinesis-test」というデータストリーム名で作成しました。
データストリームの容量

データストリームの容量はの設定では、容量モードとして「オンデマンド」と「プロビジョンド」の2つがあります。
「オンデマンド」はデータストリームのスループットが予測できない場合に使用します。書き込み容量のために最大で 200 MiB/秒および 200,000 レコード/秒のトラフィックに対応するようにスループットを自動的にスケールします。
「プロビジョンド」の場合は、スループットの要件を推定できる場合に選択します。
ストリームの合計容量は、シャード数によって決定されるので、事前にスループット要件がわかっている場合は、それに応じてシャード数を決定します。
各シャードは最大 1 MiB/秒および 1,000 レコード/秒まで取り込み、最大 2 MiB/秒まで発行します。
データストリーム設定
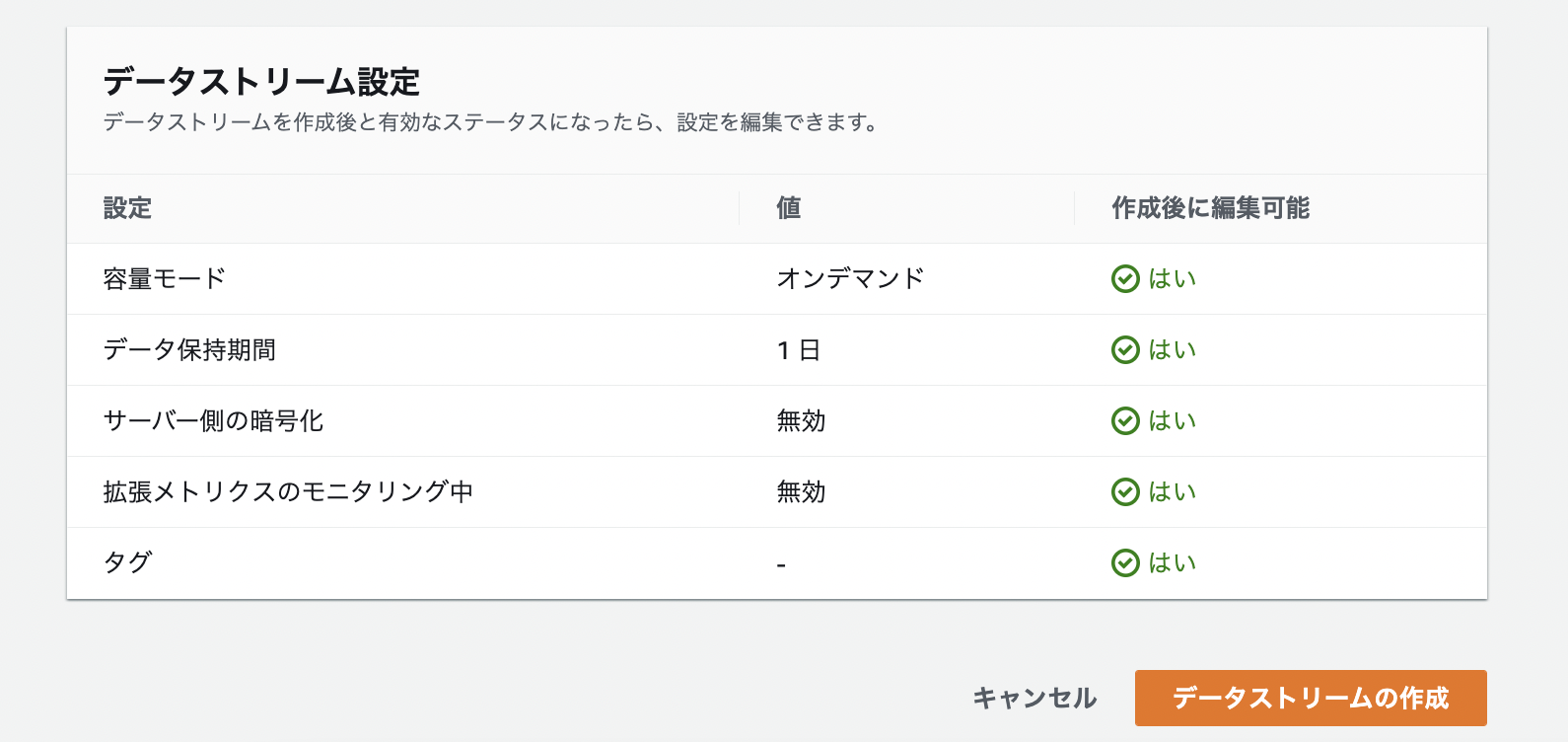
容量モード
一つ上のデータストリームの容量の設定で「オンデマンド」を選択したので、それが値として表示されています。
データ保持期間
データレコードは一時的にシャードに保存され、レコードが追加されてからアクセスできなくなるまでの期間を保存期間と言います。デフォルトは保存期間は1日になっています。最大で365日です。
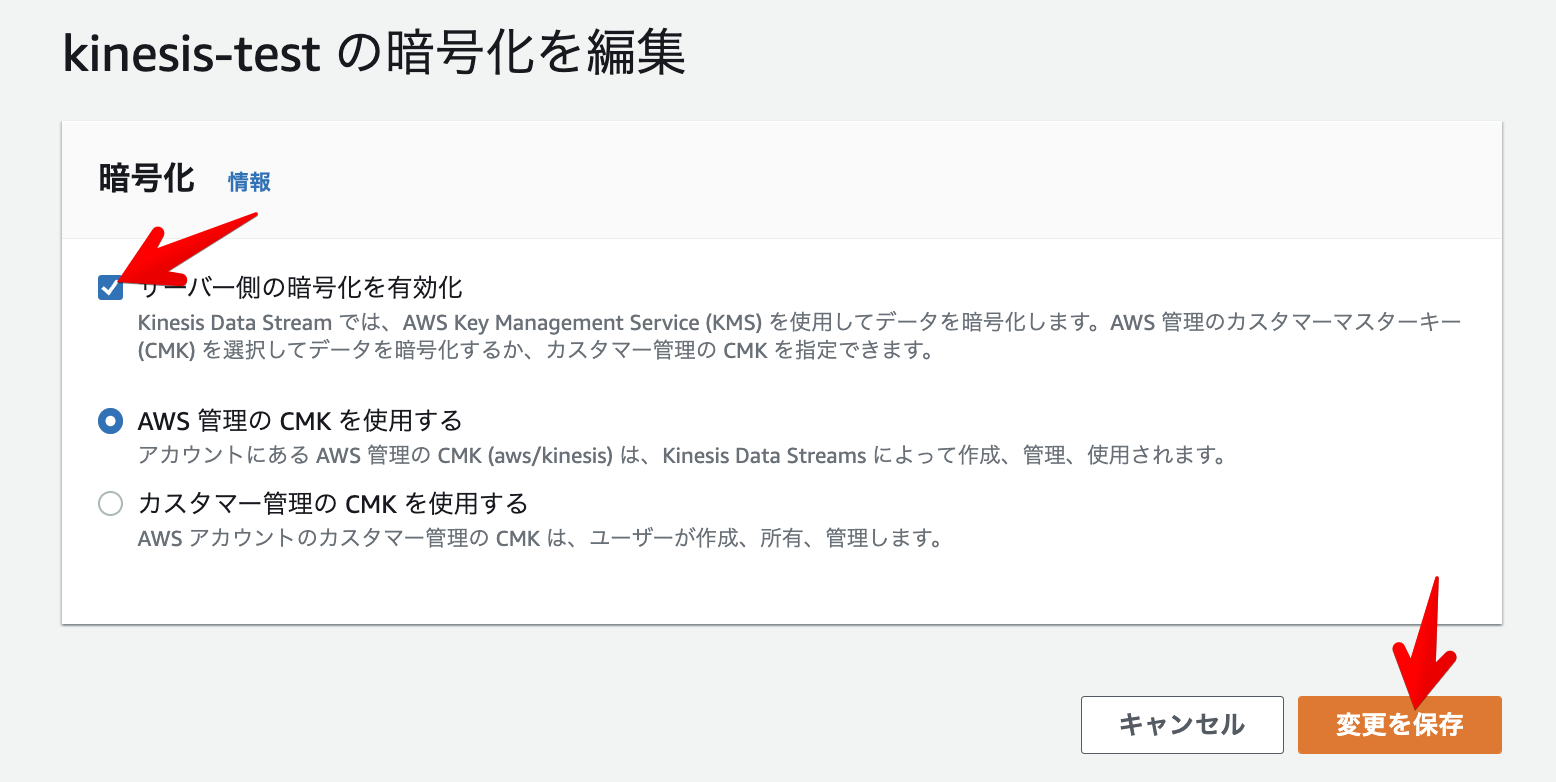
サーバー側の暗号化
Kinesisデータストリームでデータを保管する前にデータを自動的に暗号化する機能です。
Kinesisストリームのストレージレイヤーに書き込まれる前に暗号化され、ストレージから取得される時に複合化されます。
現状は無効というステータスになっています。
Kinesis Data Streams 用のサーバー側の暗号化とは?
データストリームの作成
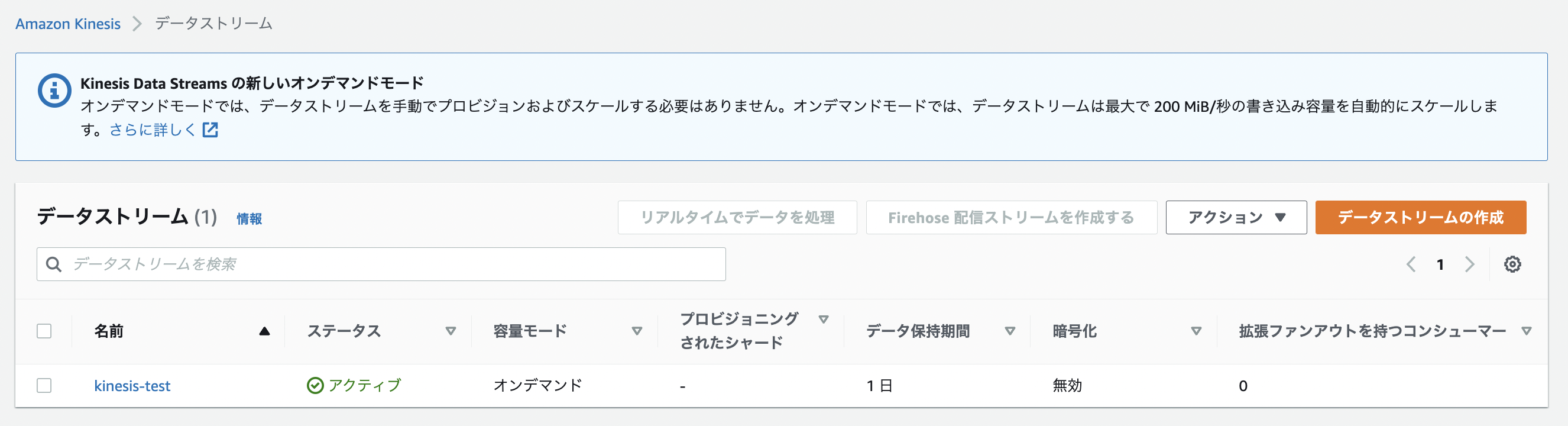
設定が完了したらデータストリームを作成します。
Lambdaへ付与するIAMロールの作成
信頼されたエンティティを選択
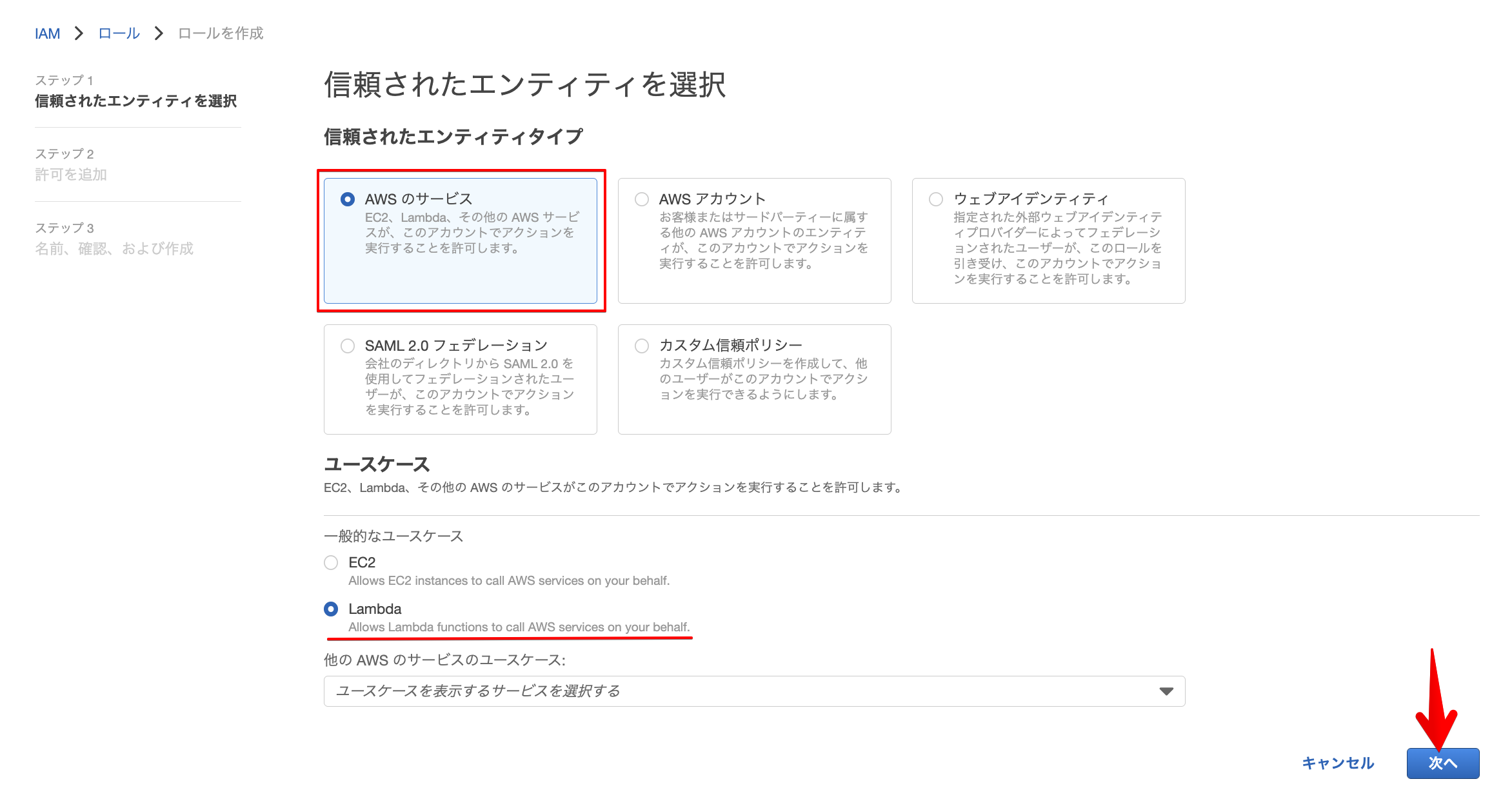
LambdaにKinesisへのアクセスとCLoudWatchへの書き込み権限を付与するIAMロールを作成します。
上記のように「AWSのサービス」「Lambda」を選択し、次へ進みます。
許可するポリシーを選択
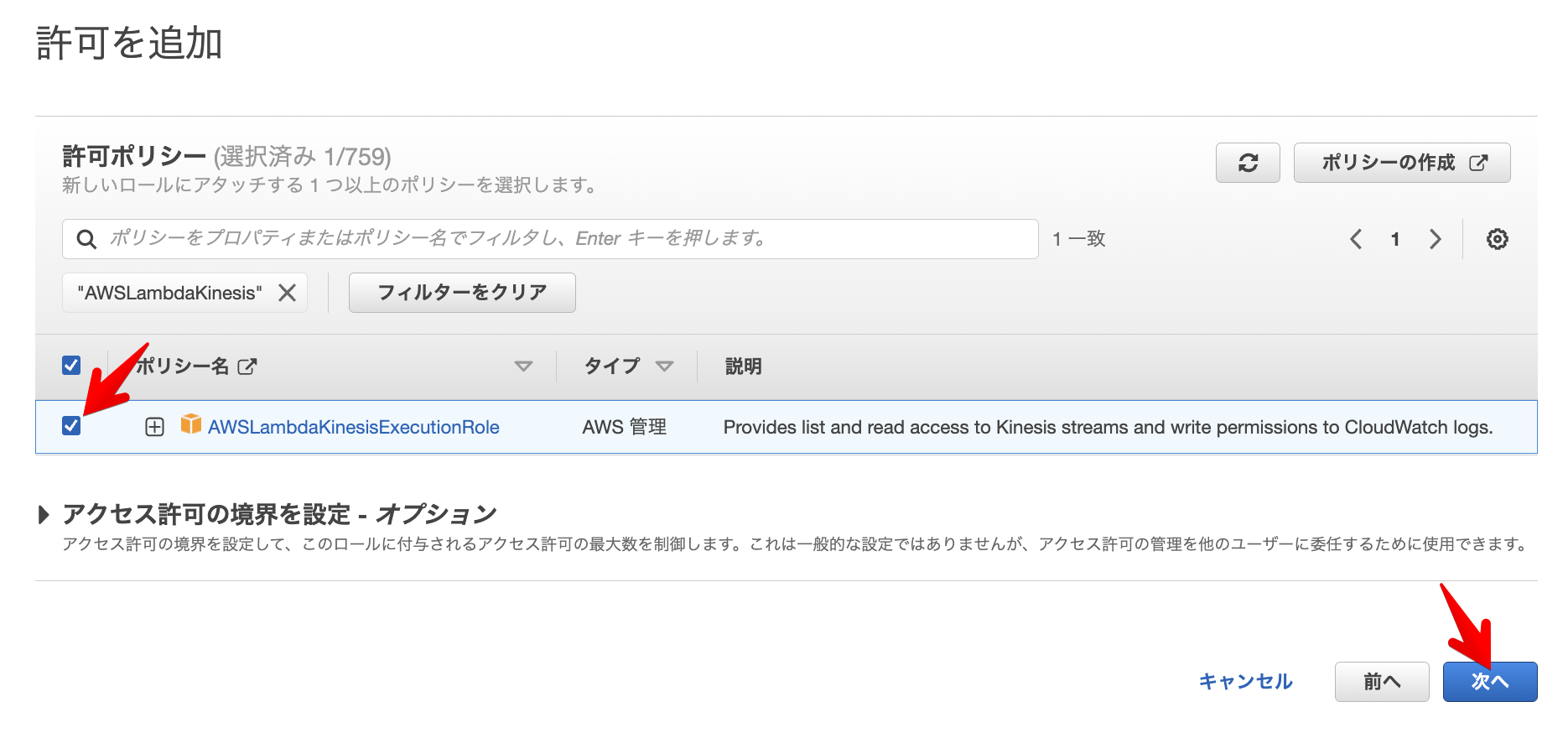
許可するポリシーに「AWSLambdaKinesisExecutionRole」を選択し次へを選択します。
LambdaがKinesisへアクセスする権限とCloudWatchへのログ出力の権限が付与されます。
ロールの作成

ロール名を指定後、ロールを作成します。
Kinesis Data Streamのデータを処理するLamdaの作成
設計図の指定
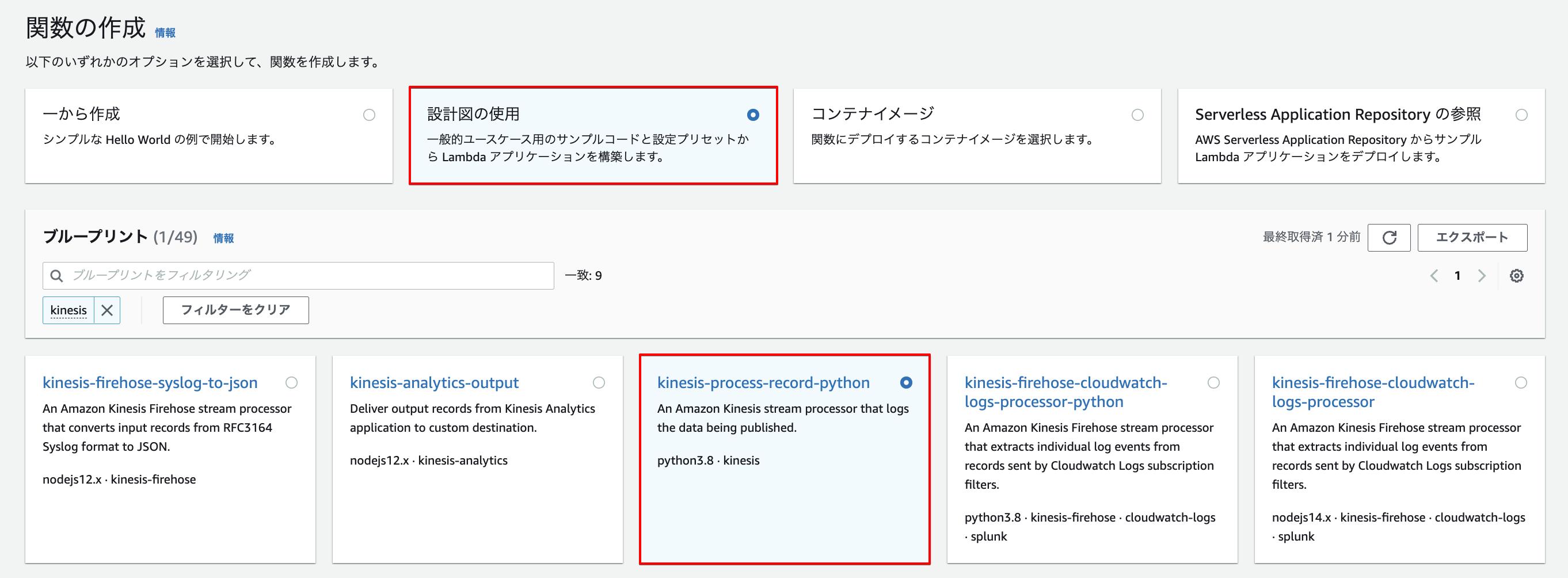
Kinesis Data Streamのデータを処理するLamdaを作成します。
今回はAWSで既に用意されているテンプレートを活用します。
Lambdaを作成するコンソール画面から「設計図の使用」と「kinesis-process-record-python」を指定します。
基本情報の設定

関数名を「kinesis-test-lambda」とし、実行ロールは先ほど作成したIAMロールを使用するため、「既存のロールを使用する」を選択します。
「既存のロール」の項目では、先ほど作成したIAMロールを指定します。
Kinesisトリガーの設定
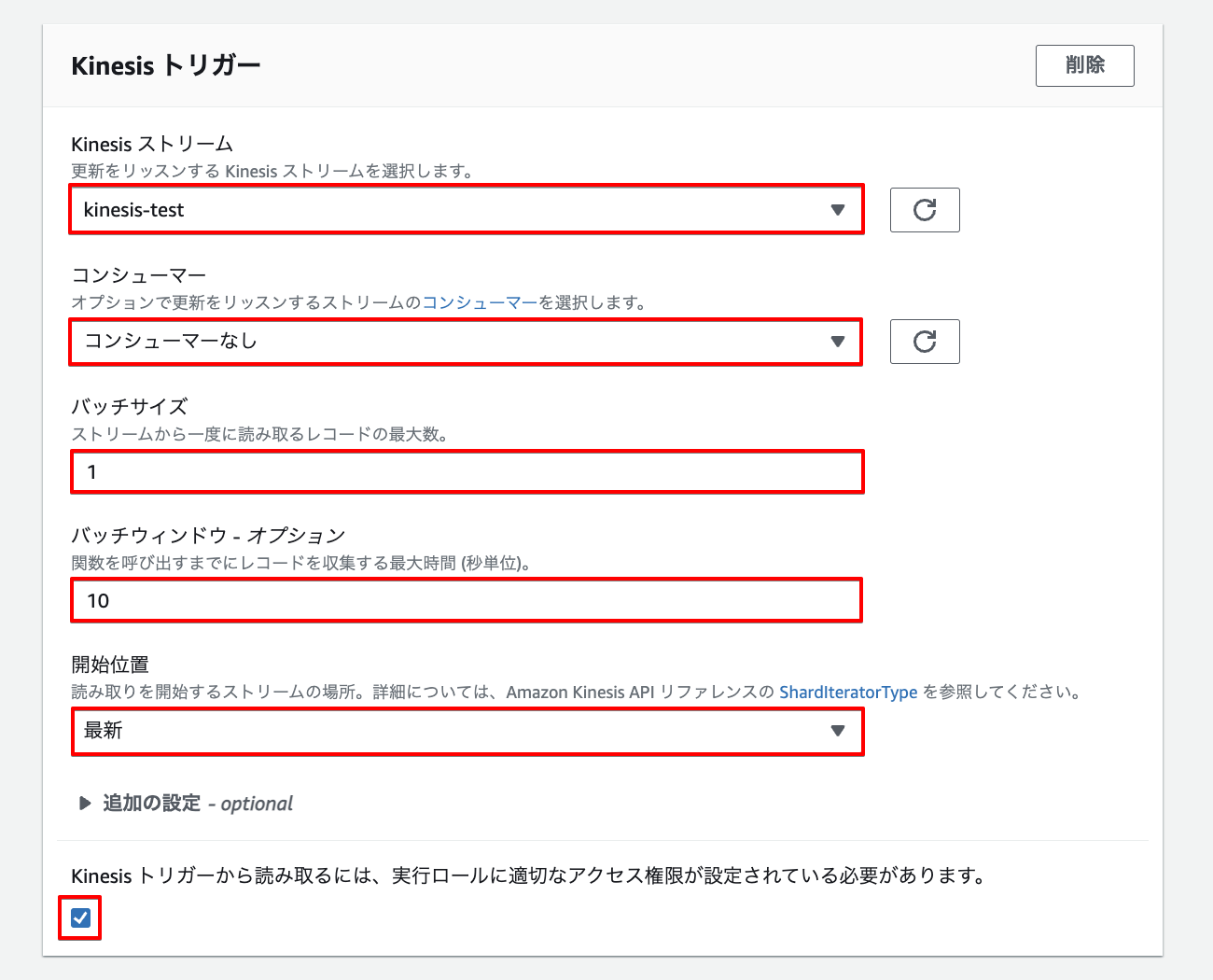
Kinesisストリーム
更新を検知するKinesisを選択します。作成した「kinesis-test」のKinesisストリームを選択します。
コンシューマー
ストリームコンシューマーにより、ストリームからデータを呼び出す際に、専用接続で通信を行うかを指定します。
ストリームコンシューマーは、ストリームから読み取る他のアプリケーションに影響を及ぼさないように、専用の接続を各シャードに割り当てます。
今回はデフォルトの「コンシューマーなし」に設定してます。
バッチサイズ
Kinesisストリームから一度に読み取るレコードの最大数値を指定しています。
今回は1件に設定しているので、Lamdbdaにより1件ずつ取得されます。
バッチウィンドウ
Lambda関数を呼び出すまでにレコードを収集する待機時間で、待機中に受信したストリーミングデータを蓄積します。
バッチサイズと合わせて待機時間を設定します。
今回は10秒としています。
開始位置
新しいレコードのみを取得するか、既存のレコードを全て取得するか、または特定の日付以降に作成されたレコードを処理するかを指定します。
今回は「最新」にしているので、ストリームに追加された新しいレコードを処理します。
参考:Amazon Kinesis で AWS Lambda を使用する
Lambda関数のコード
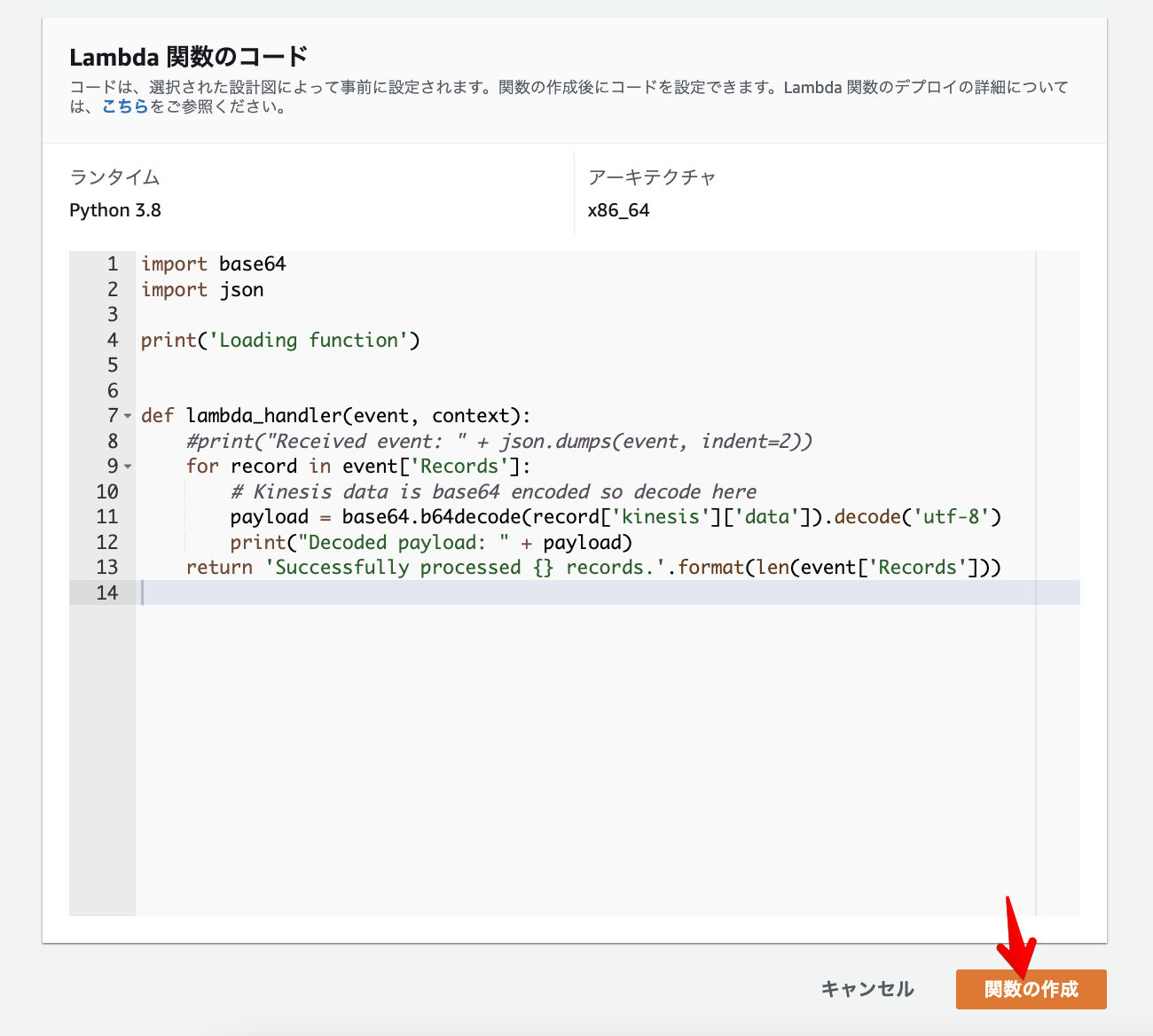
eventに渡された配列「Records」をRecord数分ループし、Kinesisのストリーミングデータを抽出し内容を表示するシンプルなプログラムです。
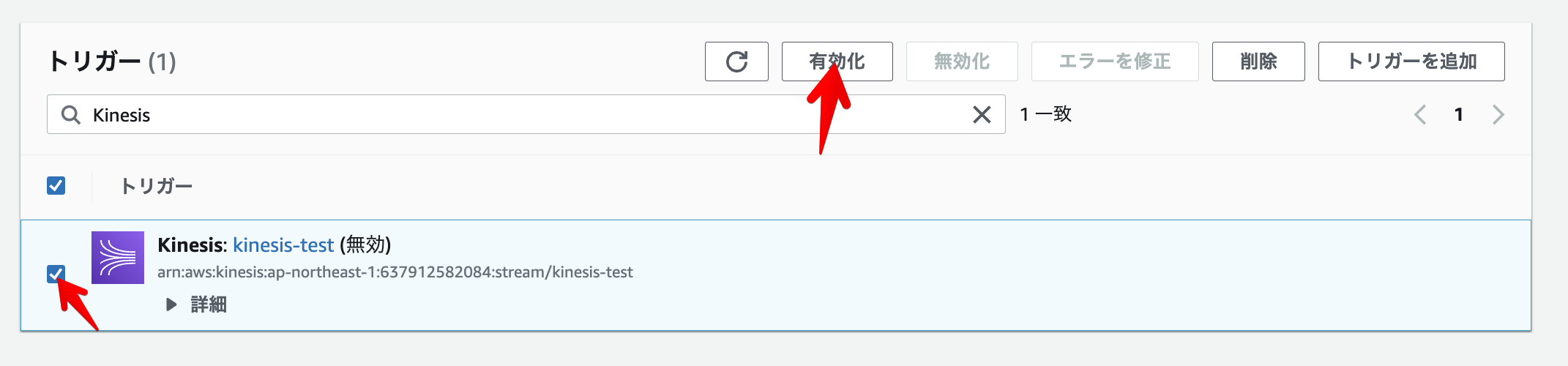
トリガーの設定
下記のようにトリガーを設定し有効化します。
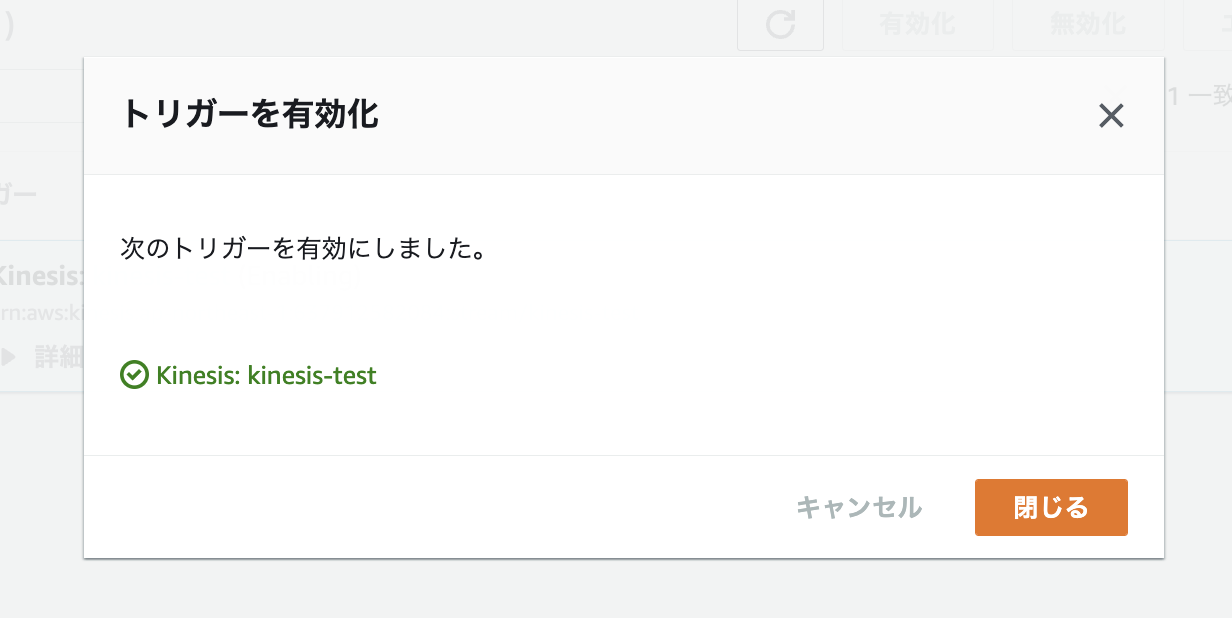
動作確認
下記のコマンドを実行し、Kinesis Data Streamにデータを挿入します。
実行後下記が出力されます。
ShardId: shardId-000000000000
実行後、Kinesis Data Streamがデータを受信し、Lambda関数が起動し、CloudWatchにログが書き込まれます。
Traceback (most recent call last):
File “/var/task/lambda_function.py”, line 11, in lambda_handler
payload = base64.b64decode(record[‘kinesis’][‘data’]).decode(‘utf-8’)
ログを確認するとデコードのところでエラーが出力されてしまいました。
Lambdaのソースコードを下記のように書き換え、デコードせずに出力することにしました。
1 2 3 4 5 6 7 8 9 | import json print('Loading function') def lambda_handler(event, context): for record in event['Records']: payload = record['kinesis']['data'] print("payload: " + payload) return 'Successfully processed {} records.'.format(len(event['Records'])) |
実行すると下記のようにログが出力され、Kinesis Data Streamに挿入したデータが出力されていることが確認できました。

原因として、そもそも暗号化されていなかったのかと考え、Kinesisの設定をサーバー側の暗号化を有効化するに設定し直し、デコード処理を追加し実行しました。
1 2 3 4 5 6 7 8 9 10 11 12 | import base64 import json print('Loading function') def lambda_handler(event, context): #print("Received event: " + json.dumps(event, indent=2)) for record in event['Records']: payload = base64.b64decode(record['kinesis']['data']).decode('utf-8') print("Decoded payload: " + payload) return 'Successfully processed {} records.'.format(len(event['Records'])) |
Kinesis側でデータを暗号化する設定を行なったものの、最初に実行した場合と同じようにデコードでエラーが出力されてしまいました。
暗号化や複合化はKinesisデータストリームで行われ、複合化された結果がLambdaには返ってくるようです。
そのため、Lambda関数では、複合化をする処理を省くとCloudWatchログにデータが出力されることが確認できます。
データの複合化の処理を省いたコードで、Kinesisで受信したデータが、受信したことをトリガーに、Lambdaが動作し、CloudWatchに「testdata」が出力されたことを確認できました。
参考:Kinesisストリームのサーバーサイド暗号を使ってみた
まとめ
Amazon Kinesis Data Streamについて調べて整理し、簡単なサンプルを通して、その動作を確認してみました。
参考
AWS CLI を使用した基本的な Kinesis Data Stream オペレーションの実行
KinesisDataStreamsのデータ処理用Lambda作成











