
どうも、とがみんです。
この記事では、Pythonを利用して、Google検索し、その結果の記事タイトルとURLを「beautifulsoup4」というライブラリを使用してスクレイピングする方法について説明します。
今回目指すもの
Pythonを使用して、検索クエリを入力し、そのクエリでGoogle検索をした際に得られる結果の記事タイトルとURLを取得し、その一覧を作成します。
以下は「Fresopiya」という検索キーワードで15件取得し、余計なリンクを省いたものです。

実装方法
実装方法について、以下の手順で説明していきます。
- 必要なライブラリのインストール
- Google検索する際のURL作成しデータを取得
- htmlデータのスクレイピング
必要なライブラリのインストール
「requests」と「beautifulsoup4」というライブラリをインストールします。
ターミナルからインストールします。
$ pip install beautifulsoup4
request
「requests」は、HTTP通信を行うためのライブラリです。
このライブラリを使用すると、Webサイト等のデータを簡単に取得することができます。
beautifulsoup4
「beautifulsoup4」は、Webサイトを構成しているHTMLファイル等から情報を抽出するために使用するライブラリです。
Google検索する際のURL作成しデータを取得
requestsライブラリをインポートし、URLを作成しリクエストを送ります。
paramsには、検索する際のクエリや、結果の取得件数を指定します。
以下のコードを実行すると、responseに受け取ったデータが格納されます。
クエリは「Fresopia」、取得件数は「5件」にしています。
1 2 3 | import requests googleSearch = 'https://www.google.co.jp/search' response = requests.get(googleSearch, params={'q': 'Fresopiya','num':5}) |
Google検索におけるパラメーターは他にもたくさんあり、以下の記事にまとめられています。
htmlデータのスクレイピング
次に、受け取ったhtmlデータのスクレイピングをします。
1 2 3 4 | from bs4 import BeautifulSoup html = response.text.encode() bs4 = BeautifulSoup(html,'html.parser') searchResults = bs4.select('.r > a') |
bs4.select(‘.r > a’)は以下の<div class = ‘r’>の中のaタグを取得しています。
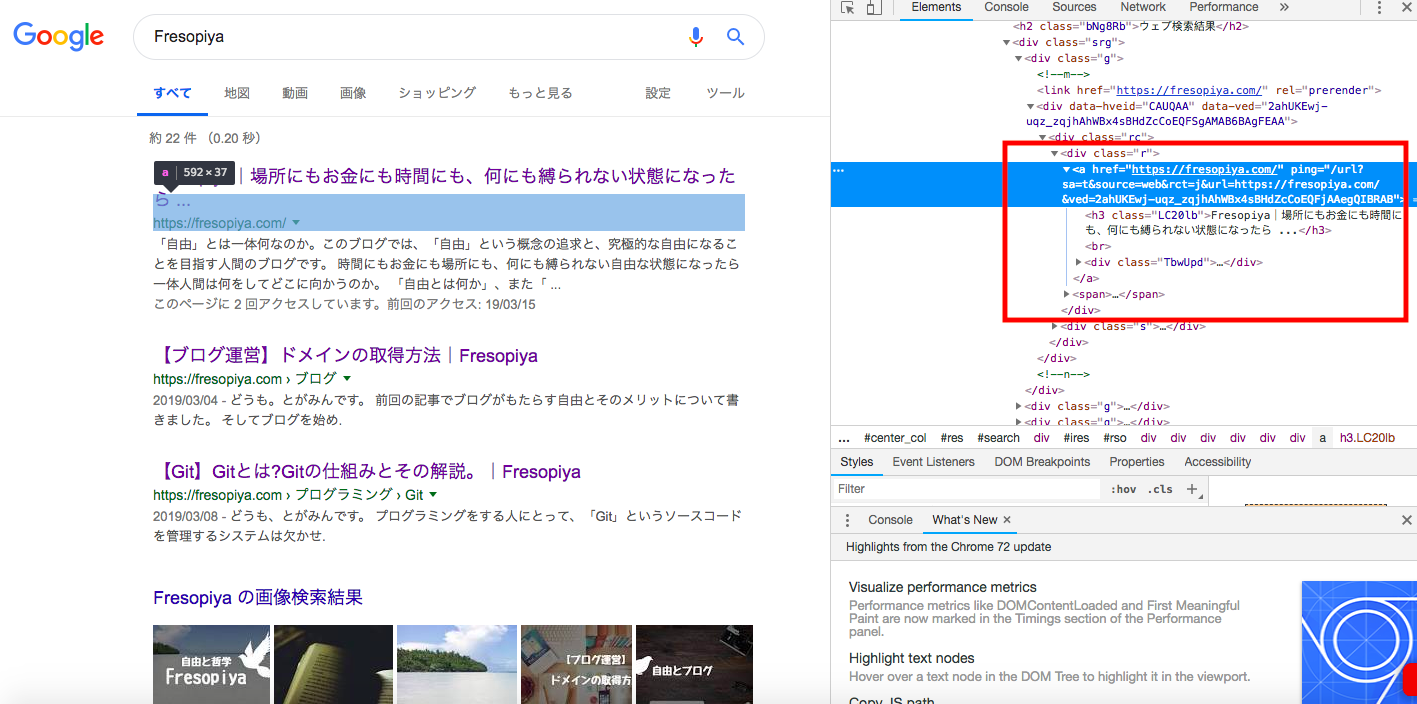
そして、以下のコードで、記事タイトルとURLを取り出しています。
1 2 3 4 5 6 | import re for searchResult in searchResults: title = searchResult.text url = re.sub("\/url\?q=","",searchResult.get('href')) print('タイトル:',title) print('URL:',url) |
このコードを実行すると、以下のような結果になります。

最後に、上記結果のhttpで始まらない画像検索結果を省き、リストにします。
1 2 3 4 5 6 7 8 | dataList = [] for searchResult in searchResults: #...省略 if re.match('http',url) != None: data = {} data['title'] = title data['url'] = url dataList.append(data) |
dataListの中身を表示すると以下のようになります。
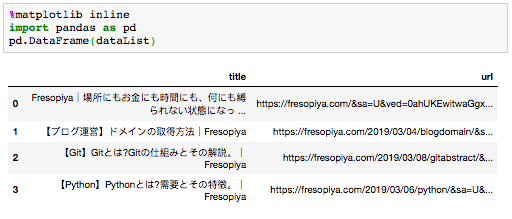
インポートしているライブラリ「re」に関しては、以下を参考にしてください。

まとめ
PythonでGoogle検索の結果を取得し「beautifulsoup4」で記事タイトルとURLを取得する方法について説明しました。
参考文献
>PythonのrequestsとBeautifulSoupでGoogle検索結果から、タイトルとURLと説明文だけを抜き取る
>[PythonでWebスクレイピングする時の知見をまとめておく













