
スポンサードリンク
どうも、とがみんです。
以前の記事で、MeCabを利用した形態素解析の方法を説明しました。

この記事では、形態素解析後の結果から、「名詞」と「動詞」のみを抽出する方法について紹介していきます。
Contents
「名詞」と「動詞」の抽出方法
以下の文章の「名詞」と「動詞」のみを抜き出します。
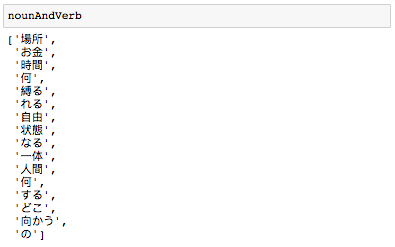
場所にもお金にも時間にも、何にも縛られない自由な状態になったら一体人間は何をしてどこに向かうのか。
以下のコードを実行し、上記文章を入力します。
1 2 3 4 5 | import MeCab mecab = MeCab.Tagger ('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd') text = input("解析する文章を入力してください:") result = mecab.parse(text) print(result) |
resultには、以下のようなデータが入っているので、これを加工し、「名詞」と「動詞」のみを取り出します。

以下のコードが、「名詞」と「動詞」のみを抽出するコードです。
1 2 3 4 5 6 7 8 9 | lines = result.split('\n') nounAndVerb = []#「名詞」と「動詞」を格納するリスト for line in lines: feature = line.split('\t') if len(feature) == 2: #'EOS'と''を省く info = feature[1].split(',') hinshi = info[0] if hinshi in ('名詞', '動詞'): nounAndVerb.append(info[6]) |
実行すると、「名詞」と「動詞」のみが格納されていることがわかります。
まとめ
形態素解析後の結果から、「名詞」と「動詞」のみを抽出する方法について紹介しました。
後、いろいろと調べていると、
MeCabの解析結果を得る方法として、parceとpareToNodeという2つのメソッドがあるのですが、pareToNodeは処理速度が遅いので使わない方が良いかもしれません。
スポンサードリンク
スポンサードリンク













