
どうも、とがみんです。
Googleのクローラーってどのようにしてデータを集めているんだろか、どのようにしてWeb上からデータを集めれば良いのか、と考えたことはあるでしょうか。
この記事では、スクレイピング用のフレームワークであるscrapyを用いて、Web上のデータをクロールし、スクレイピングする方法について紹介していきます。
今回目指すもの
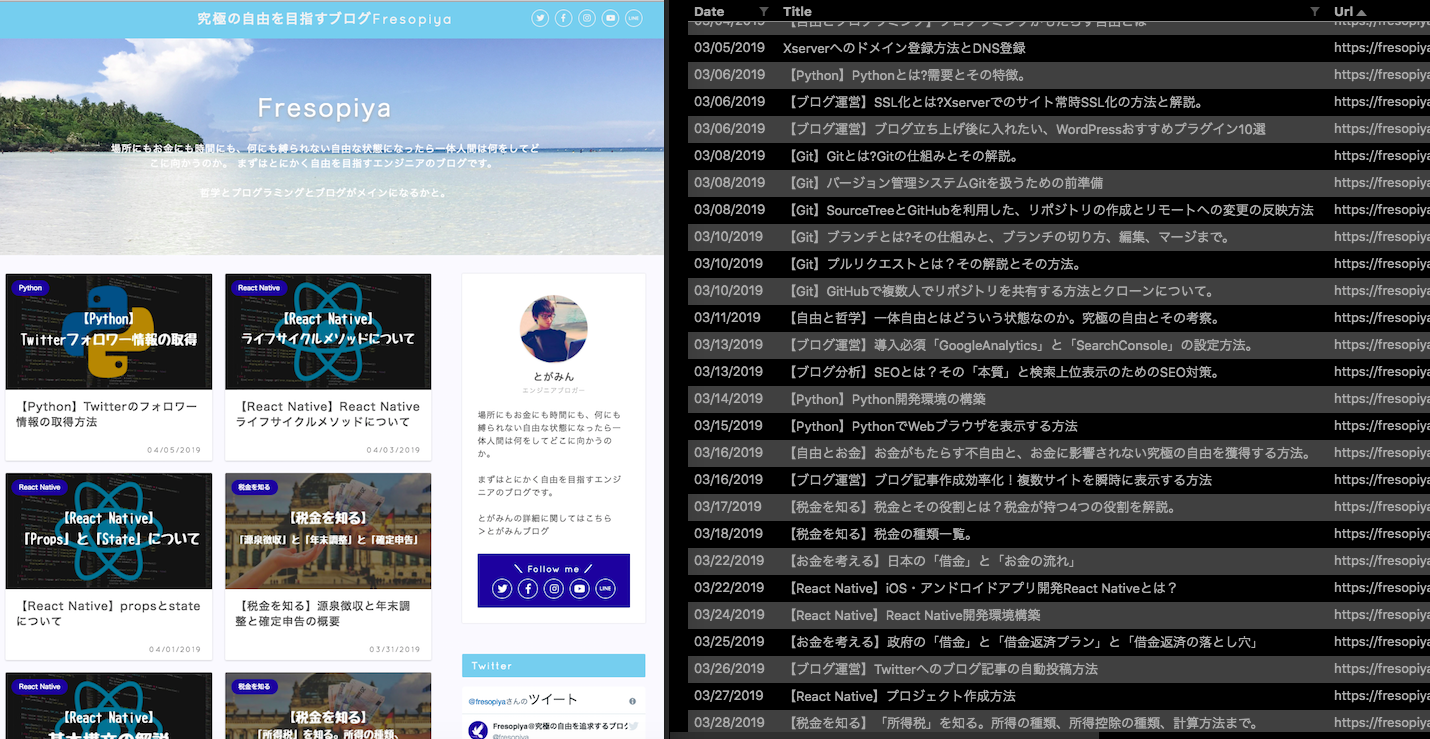
今回目指すのは、以下写真のブログ「Fresopiya」のブログをクロールし、全てのブログの記事の「更新日時」、「記事タイトル」、「記事URL」を取得するプログラムを書いていきます。
scrapyの詳細
まず、「scrapy」について紹介します。
「scrapy」はクローリング、スクレイピングするためのPythonのフレームワークです。
クローリングとは、プログラムがインターネット上のリンクを辿ってWebサイトを巡回し、データを収集する行為のことで、
スクレイピングとは、収集したデータから、必要な情報を抜き出す行為のことです。
以下の図は「Scrapy」の概要についてです。「scrapy」を構成する要素やデータのフローを示しています。
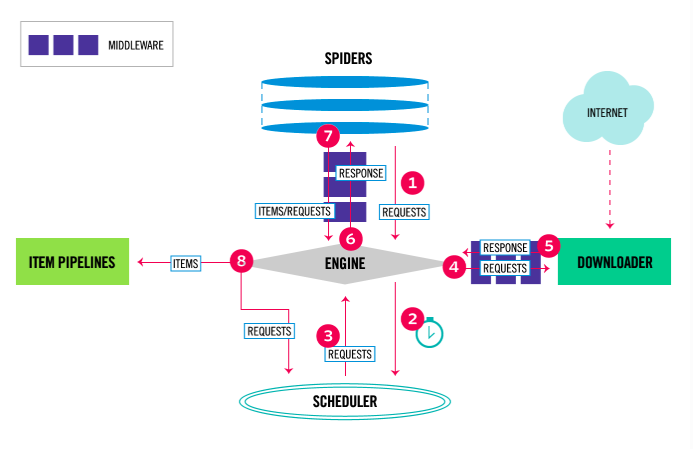
>引用:Architecture overview|scrapy
| 主要コンポーネント | 役割 |
|---|---|
| ENGINE | コンポーネント間のデータのフローの制御。 特定のアクションが発生したら、イベントを発生させる。 |
| SCHEDULER | Engineから受け取ったリクエストをエンキューする。 |
| DOWNLOADER | ダウンロードの処理。 |
| SPIDERS | 取得したいURLや抽出したい部分を記述し、ダウンロードしたコンテンツをスクレイピングして、Itemを作成。 |
| ITEM PIPELINES | SPIDERSによって抽出されたアイテムの出力処理 |
上の図のフローについてです。
- Engineは、Spiderからクロールする最初のリクエストを取得します。
- Engineは、Schedulerにスケジュールし、Schedulerに、次のリクエストを要求します。
- Schedulerは、次のリクエストをEnginに返します。
- EnginはSchedulerから受け取ったリクエストをDownloaderに送信します。
- ページのダウンロードが完了すると、それをEnginに返します。
- EnginはDownloaderからのレスポンスを受け取り、Spiderに送信します。
- Spiderはレスポンスを処理し、収集したデータとつぎのリクエストをEngineに返します。
- Engineは処理されたアイテムをItem Pipelineに渡し、処理が完了したことをSchedulerに伝え、次のリクエストを要求します。
これらのプロセスは、Schedulerに溜まっているクロールをするリクエストがなくなるまで繰り返されます。
「scrapy」の仕組みはこんな感じです。
実装方法
次に実装方法について紹介していきます。
ライブラリのインストール
ターミナルで以下のコマンドを実行し、scrapyをインストールします。
プロジェクトの作成
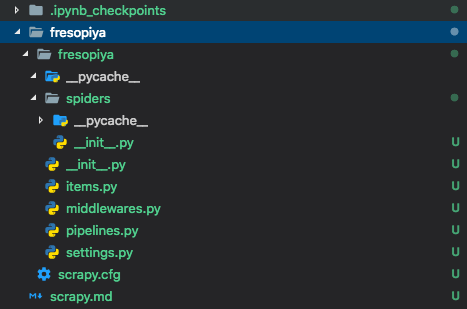
以下のように$ scrapy startproject プロジェクト名をターミナルで実行すると、現在いるディレクトリに新しくフォルダが作成されます。
以下はプロジェクト名をfresopiyaとした時に作成されたファイルです。
Itemsの作成
Items.pyにサンプルのクラスが記述されているので、以下のように収集したい項目をコードに書きます。
ブログ記事のURL、タイトル、公開日を格納するクラスを作成します。
1 2 3 4 | class FresopiyaItem(scrapy.Item): url = scrapy.Field() title = scrapy.Field() date = scrapy.Field() |
Spiderの実装
spidersディレクトリに移動し、spiderファイルを作成します。
scrapy genspider スパイダー名 クロール対象ドメインコマンドを打ち作成します。
作成したファイルを以下のように変更します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # -*- coding: utf-8 -*- import scrapy #作成したItemを読み込む from fresopiya.items import FresopiyaItem class ScrapyFresopiyaSpider(scrapy.Spider): name = 'scrapy_fresopiya' allowed_domains = ['fresopiya.com'] start_urls = ['http://fresopiya.com/'] def parse(self, response): for article in response.css('article.post-list-item'): item = FresopiyaItem() item['url'] = article.css('a.post-list-link::attr(href)').extract_first() item['title'] = article.css('h2.post-list-title ::text').extract_first() item['date'] = article.css('span.post-list-date ::text').extract_first() yield item #次のリンクを抜き出して辿る。 for next_page in response.css('a.inactive::attr(href)'): yield response.follow(next_page, self.parse) |
start_urlsに指定したURLからクロールがスタートします。
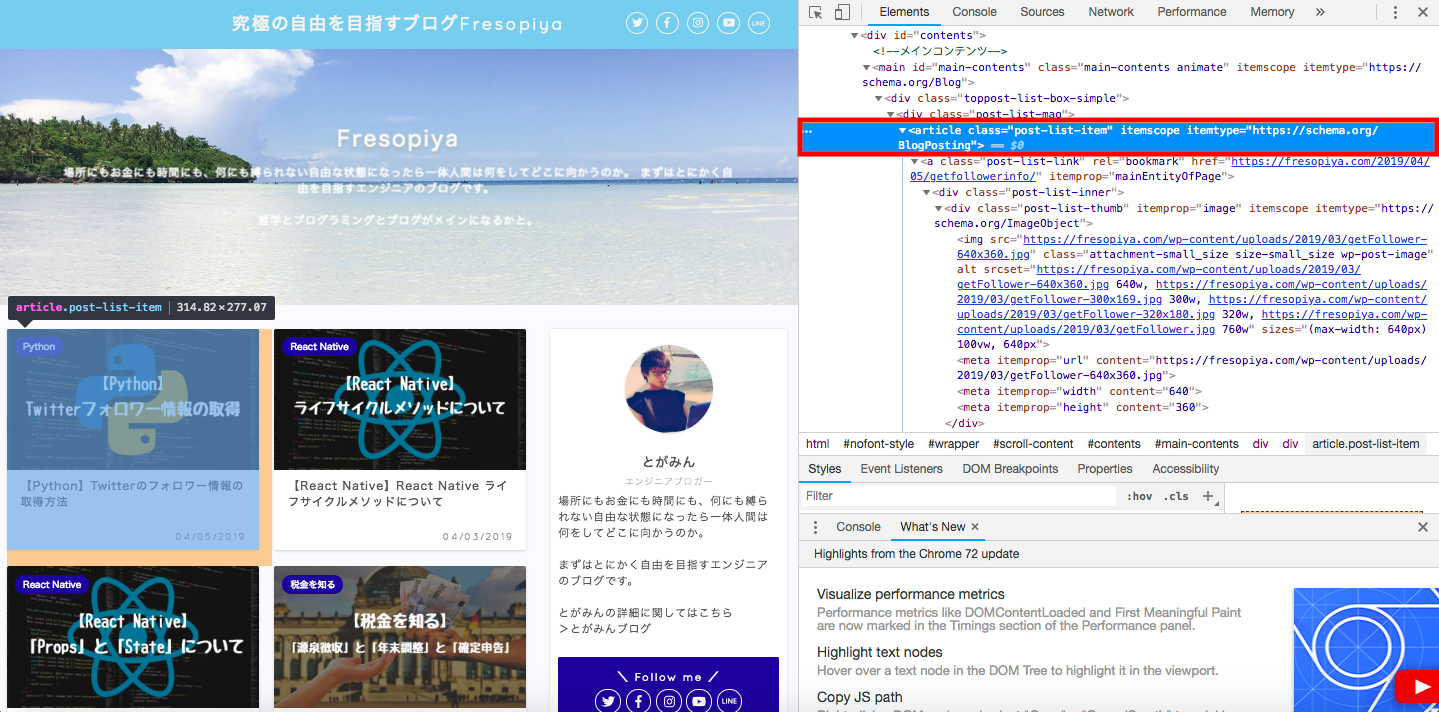
response.css(‘article.post-list-item’)は、下図の赤枠で囲っているタグの情報を抜き出しています。class がpost-list-itemのarticleタグごとにfor文の中身が実行されます。
itemの各キーの値に取得したデータを格納していきます。
yieldについては以下の記事を参考に。
>python の yield。サクッと理解するには return と比較
Setting
設定についてです。settings.pyというファイルがあるので、そこに各種設定をしていきます。
1 2 3 | DOWNLOAD_DELAY = 3 DEPTH_LIMIT = 1 ROBOTSTXT_OBEY = True |
| 設定 | 概要 |
|---|---|
| DOWNLOAD_DELAY | 1つのページをダウンロードしてから、次のページをダウンロードするまでの間隔。 |
| DEPTH_LIMIT | クロールできる最大の深さ。 |
| ROBOTSTXT_OBEY | robots.txtポリシーを尊重するかどうか。 |
設定項目は他にもあります。
プログラムの実行
ターミナルにて、scrapy_fresopiya.pyのファイルがあるディレクトリまで移動し、以下のコマンドを実行します。
上記のコマンド実行すると、サイトをクロールし取得したデータをCSVファイルとして出力してくれます。fresopiyaitems.csvというファイルが生成されます。
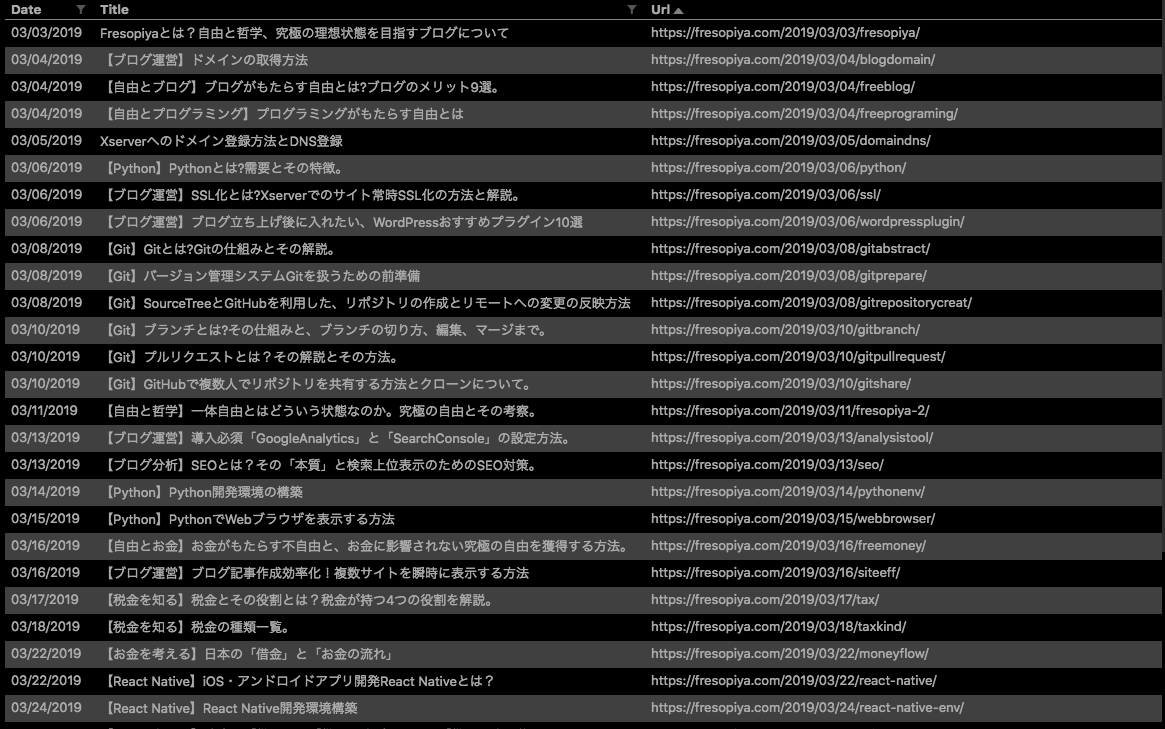
これで、このブログの全ての記事の「更新日時」、「記事タイトル」、「記事URL」が取得できました。
まとめ
スクレイピング用のフレームワークである「scrapy」を用いて、Web上のデータをクロール、スクレイピングする方法について紹介しました。
実際にクローラーを作ってみることで、Googleのクローラーがどのようにして、データを収集しているのかのイメージがつくのではないでしょうか。
また、データの収集するにあたって、強力なツールになると思うので、是非試してみてください!
参考文献
>Scrapy入門① とりあえずクローラーを作って実行し、Webサイトからデータを取得してみるとこまで
>Python, Scrapyの使い方(Webクローリング、スクレイピング)














