
どうも、とがみんです。
以前の記事では、類似度の高いデータをクラスタリングするためのk-means法のアルゴリズム、仕組みについて紹介しました。

この記事では、「scikit-learn」を用いて、k-means法により、「卸売業者の顧客データ」の顧客をクラスタリングしていきます。
今回すること
今回「scikit-learn」という機械学習用ライブラリを使用して、UCバークレー大学にて公開されている「卸売業者の顧客データ」を利用します。
準備されているデータは以下です。
卸売業の顧客データ
Channel:販売チャネル。1: Horeca (ホテル・レストラン・カフェ), 2: 個人向け小売
Region:各顧客の地域。1: リスボン市, 2: ポルト市, 3: その他
Milk:生鮮品の年間注文額
Grocery:食料雑貨の年間注文額
Frozen:冷凍食品の年間注文額
Detergents_Paper:衛生用品と紙類の年間注文額
Delicassen:惣菜の年間注文額
これらのデータから、この卸売業者が、どのような顧客タイプの人と取引を行なっているのかを分析して行きます。
データの準備
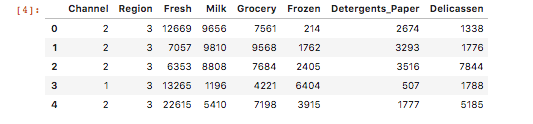
データの準備をします。以下のコードを実行すると、UCバークレー大学にて公開されている「卸売業者の顧客データ」が440件読み込まれ、最初の5つを表示します。
1 2 3 | import pandas as pd cust_df = pd.read_csv("http://pythondatascience.plavox.info/wp-content/uploads/2016/05/Wholesale_customers_data.csv") cust_df.head() |
分析の手順
分析の手順は以下のように行っていきます。
- Horecaと個人向けのデータを分割
- 分割後、それぞれで、k-means法によりクラスタリング
- データを解釈する
Horecaと個人向けデータを分轄
どのような顧客タイプかを分析するに当たって、Horecaと個人向けは顧客タイプがそもそも違うので、あらかじめ分けておきます。グルーピングの結果何か施策を行うとなった際に、アプローチの方法が変わることが予測できるので。
1 2 | cust_horeca_df = cust_df[cust_df['Channel']==1] cust_individual_df = cust_df[cust_df['Channel']==2] |
cust_horeca_dfにホテル・レストラン・カフェ、cust_individual_dfに個人向けのデータが格納されます。
分割後、それぞれで、k-means法によりクラスタリング
「ホテル・レストラン・カフェ」と「個人向け」のデータに分割したのですが、今回は、「ホテル・レストラン・カフェ」のみをクラスタリングします。
k-means法で分析するにあたって、その準備をします。
クラスタ数は3つにしています。
1 2 3 4 5 6 7 8 9 10 11 12 13 | from sklearn.cluster import KMeans clusterNum = 3 km = KMeans( n_clusters=clusterNum, #クラスタ数 init='k-means++', n_init=10, max_iter=300, #繰り返し回数の最大値。 tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1) |
各パラメータは以下です。
| パラメータ | 説明 |
|---|---|
| n_clusters | クラスターの数 |
| init | k-means++:初期のk個のクラスタの中心を離すことで、初期値問題を解決する。 random:初期クラスタの割り当てをランダムに行う。 |
| n_init | 異なる重心を用いたアルゴリズムの実行回数。 |
| max_iter | 繰り返し回数の最大値 |
| tol | 収束判定の許容可能誤差 |
| precompute_distances | データのばらつきを事前に計算するか。 |
| verbose | 1なら、分析結果を詳細表示。 |
| random_state | 乱数生成器の状態。 |
| copy_x | 距離を事前に計算する場合、メモリ内でデータを複製してから実行するかどうか。 |
| n_jobs | 並列処理で初期化する際の多重度。 |
>sklearn.clusterlear.KMeans|scikitlearn
次に、「ホテル・レストラン・カフェ」の結果をグラフ化します。
1 2 3 4 5 6 7 8 | # 可視化(積み上げ棒グラフ) import matplotlib.pyplot as plt clusterinfo = pd.DataFrame() for i in range(clusterNum): clusterinfo['cluster' + str(i)] = cust_horeca_df[cust_horeca_df['cluster_id'] == i].mean() clusterinfo = clusterinfo.drop('cluster_id') my_plot = clusterinfo.T.plot(kind='bar', stacked=True, title="Mean Value of "+ str(clusterNum) + " Clusters") my_plot.set_xticklabels(my_plot.xaxis.get_majorticklabels(), rotation=0) |
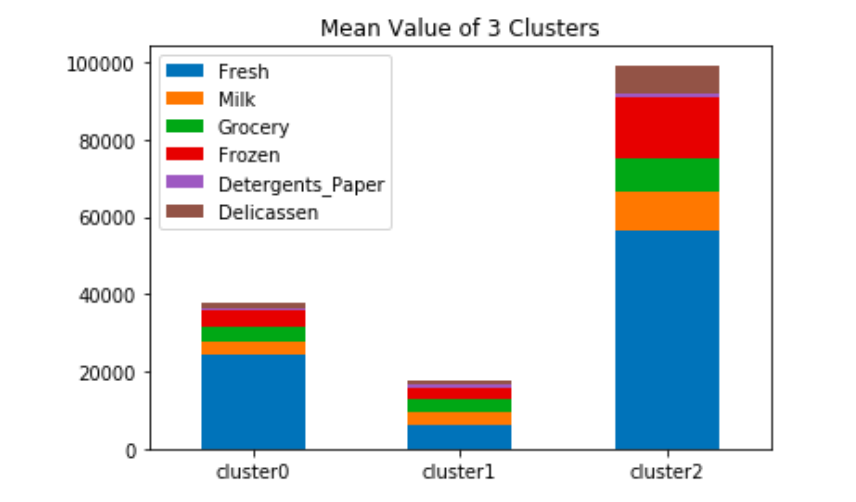
このグラフは各クラスタの平均値を取り、棒グラフで可視化したものです。
クラスタ0に振り分けられた数は83件、クラスタ1に分けられた数は202件、クラスタ2に振り分けられたのは13件でした。
データを解釈する
クラスタリングは、出来上がったクラスタに人間の主観で意味を検討しする必要があります。
クラスタ0の特徴は、生鮮食品が占める割合が多く、
クラスタ1は、全体の注文額が断突で多くなっています。
クラスタ2は全体の注文が最も少なく、件数が最も多く振り分けられていました。
クラスタリングすることによって、出来上がったクラスタからそのクラスタがどのような特徴を持つのかを類推することができるようになります。
しかし、このクラスタリングは、結果が初期値に依存したり、クラスター分析は分類するだけなので、相関関係や因果関係まではわかりません。
なので、このクラスター分析だけで、業務等にアクションの検討は難しく、相関分析や、回帰分析を行うことで、より精度の高い予測を実現し、アクションに繋げるような使われ方が多いです。
また、幾つのクラスタに分割するのかについては、いろいろ試してみて、データをうまく説明できる数を探る必要があります。
以下の図はPCA分析(主成分分析)によって次元を3次元、2次元に落とし、可視化したものです。(色はクラスタの色で、Fresh、Milk、Groceryではありません。)
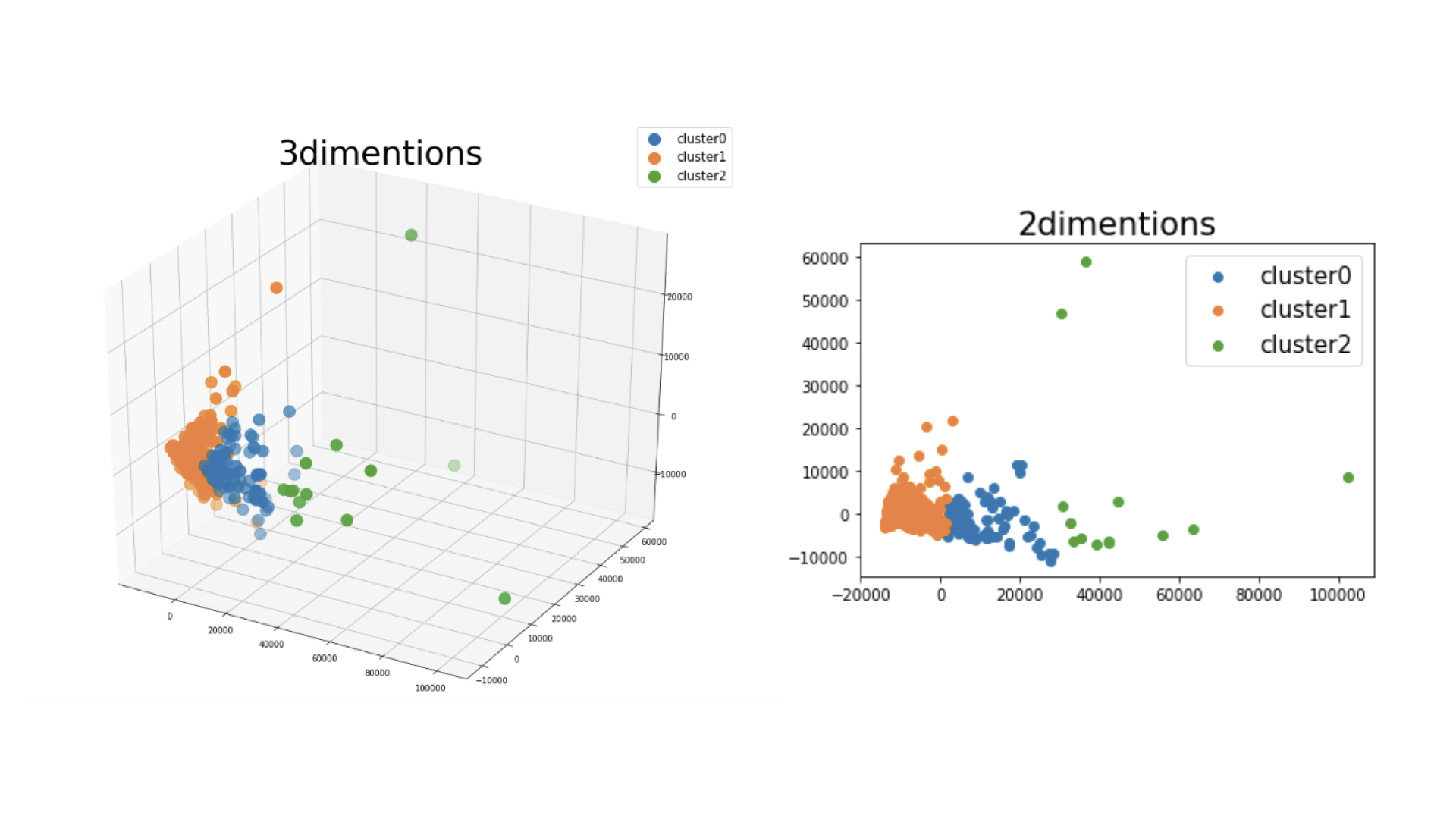
>【scikit-learn】iris(アイリス)データの主成分分析による次元削減と視覚化
どのように分割されたのかのイメージを視覚化することで、分割するクラスタ数が妥当かどうかを判断する要素になります。
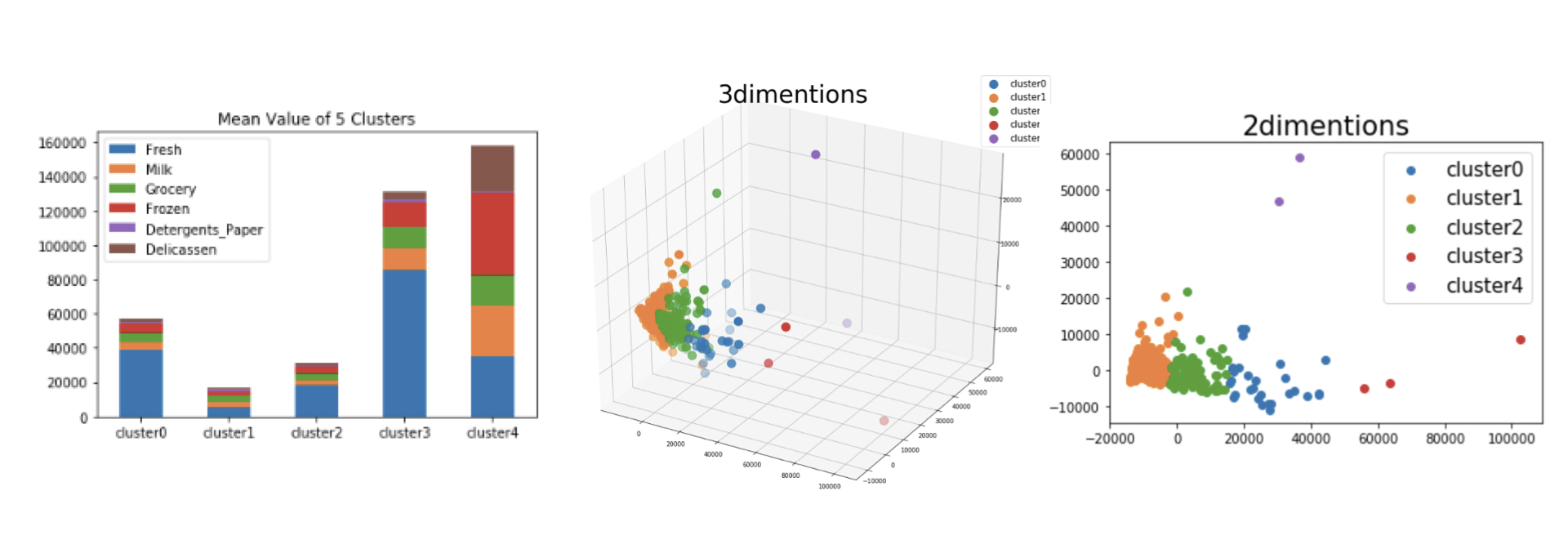
ちなみに以下はクラスタ数を5つにした時の結果です。3つのクラスタに分類した際、「cluster2」の広がりが大きいので、以下のように5つに分類した方がいいのか?とか。
具体的な使用例としては、類似度が高い顧客にクラスタリングした後、各クラスタの顧客はどういう商品を買いやすいのか等の相関分析を行い、顧客に合わせたメッセージ送信や、様々な施策につなげていきます。
まとめ
「scikit-learn」を用いて、k-means法により、「卸売業者の顧客データ」の顧客をクラスタリングし、その結果を解釈していきました。
クラスタリング単体では、業務等にアクションを起こす結果を得ることが難しいので、他の分析手法を組み合わせ考える必要があります。
参考文献
>scikit-learn でクラスタ分析 (K-means 法)
>sklearn.clusterlear.KMeans|scikitlearn












