
どうも、とがみんです。
この記事では、「分類」や「予測」でよく使われる決定木について、そのアルゴリズムとメリット、デメリットについて紹介していきます。
Contents
決定木(Decision Tree)とは
決定木分析は「予測」や「判断」、「分類」を目的として使われる分析手法です。
幾つもの判断経路とその結果を、木構造を使って、以下のようにそれらを行っていきます。

上記の図は、ペンギン、トカゲ、ライオン、ブンチョウ、ウシを「鳥類」、「哺乳類」、「爬虫類」に分類する決定木です。
この決定木分析の活用範囲は広く、様々な業種、業態で活用されています。
例えば、金融機関の取引履歴から顧客属性別の貸し倒れリスクを測ったり、
機械の動作ログから故障に繋がる指標を見つけ出したりといったことに使われます。
決定木の作り方
決定木を作る際は、どのような質問をどの順番で行うか決める必要があります。
Yes/Noで回答する質問があったとして、Yesが常に真で、Noが常に偽を表すのが最も理想的です。
例えば、「犬」かどうかを分類するための質問を考えるに当たって、
「それは羽があるかどうか」と言った質問は、すべての犬には羽はなく、羽がある犬はいないので、理想的な質問だと言えます。
逆に、「毛の色が白色かどうか」と言った質問は、毛の色が白色の犬もいれば、そうでない犬もいるので、良い質問であるとは言えません。
適切な質問を適切な順番にしていくに当たって、
与えられたデータから適切な決定木を作成するアルゴリズムとして、主に
「ID3(Iterative Dichotomiser 3)」、「C4,5(C5.0)」、「CART」、「CHAID」があります。
今回は決定木の最も基本的なアルゴリズムである「ID3」について紹介していきます。
ID3(Iterative Dichotomiser 3)
この方法は、各独立変数に対し、変数の値を決定した場合における平均情報量の期待値を求め、
その中で最大のものを選び、それを木のノードにする操作を再帰的に行うことによって作成されます。
以下の学習データをもとに、鳥類、哺乳類、爬虫類を分類するための決定木を作成します。
| 食性 | 発生形態 | 体温 | 分類 | |
|---|---|---|---|---|
| ペンギン | 肉食 | 卵生 | 恒温 | 鳥類 |
| ライオン | 肉食 | 胎生 | 恒温 | 哺乳類 |
| ウシ | 草食 | 胎生 | 恒温 | 哺乳類 |
| トカゲ | 肉食 | 卵生 | 変温 | 爬虫類 |
| ブンチョウ | 草食 | 卵生 | 恒温 | 鳥類 |
アルゴリズムの流れはざっくり以下のような感じです。
- ルートノードNを作成し、全データを所属させる。
- Nに所属するデータが、全て同じ分類先なら、処理を終了する。
- Nに所属するデータのばらつき度合い(平均情報量)を計算する。
- 各変数を質問とした時のばらつき度合い(平均情報量)を求める。
- 各変数を質問としたときの情報利得を計算する。
- 情報利得が最も大きい質問を選択し、それをノードとし、分割後のデータを新たなデータの集合とみなし、上記操作を繰り返す。
それぞれについて説明していきます。
1.ルートノードNを作成し、全データを所属させる。
以下のようにルートノード「N」を作成し、ペンギン・ライオン・ウシ・トカゲ・ブンチョウの全データをそこに所属させます。

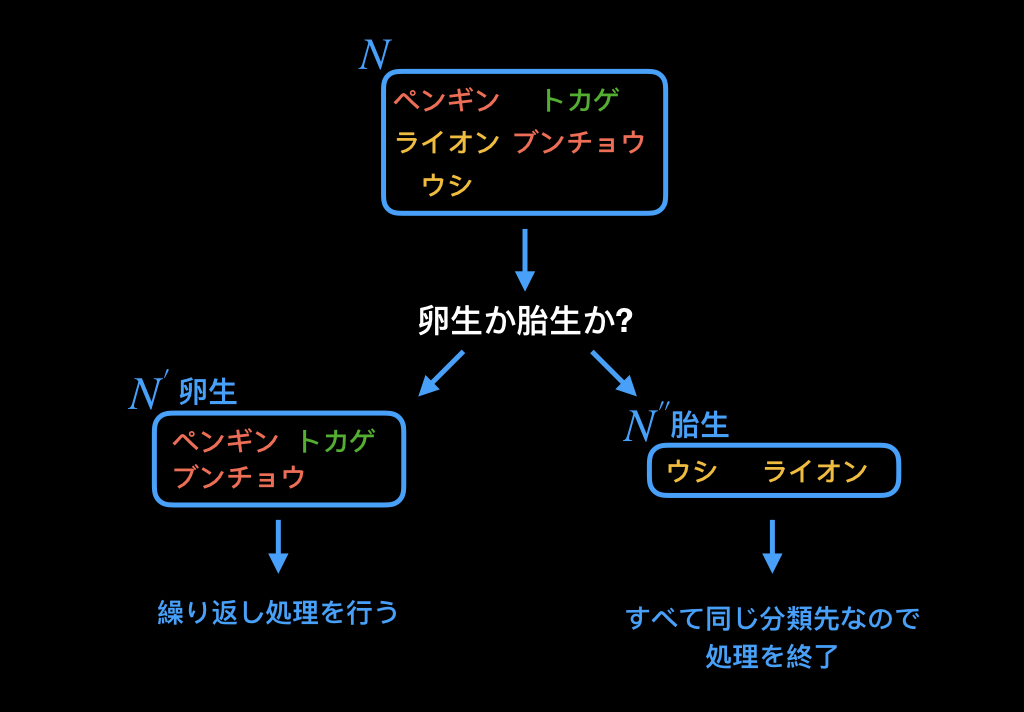
2.Nに所属するデータが、全て同じ分類先なら、処理を終了する。
Nに所属するデータが、全て同じ分類先なら、処理を終了します。
Nの中には、分類先である哺乳類、爬虫類、鳥類が混じっているので、次に進みます。
3.Nに所属するデータのばらつき度合い(平均情報量)を計算する。
Nに所属しているデータのばらつき度合い、平均情報量を計算します。

4.各変数を質問とした時のばらつき度合い(平均情報量)を求める。
食性がどうか、発生形態がどうか、体温がどうかといった、それぞれの質問をした場合、それぞれの結果の平均情報量の平均(期待値)を計算します。
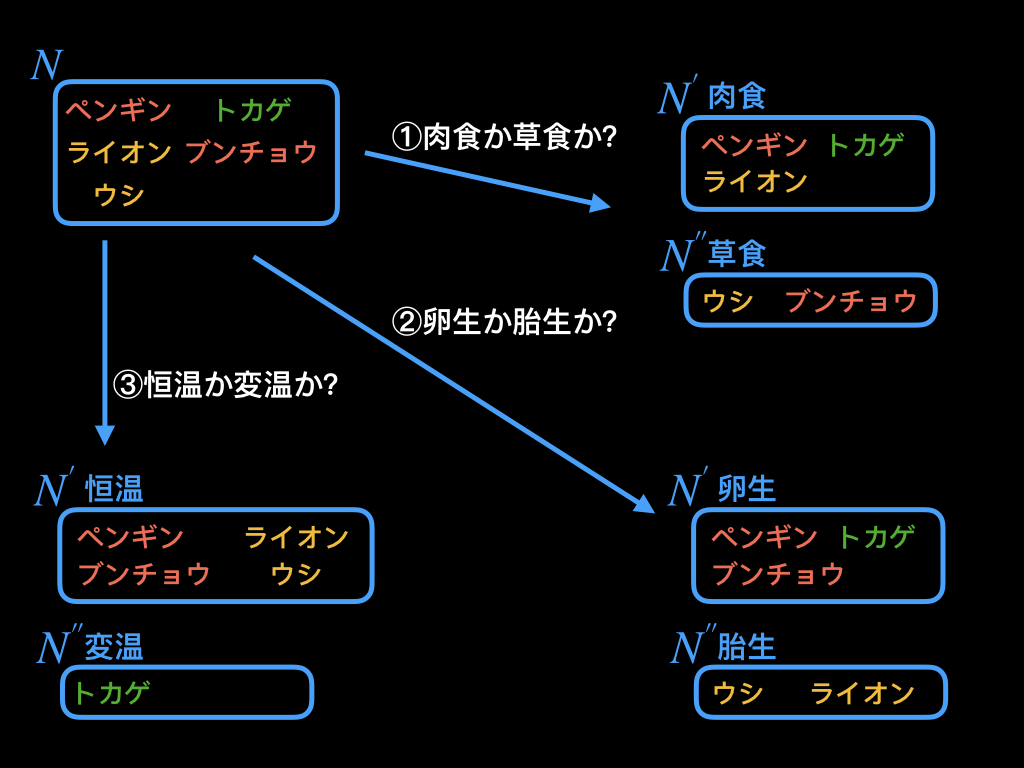
以下が、それぞれの質問の結果、平均情報量がどうなるのかを計算したものです。

肉食か草食かで分類した場合の平均情報量の平均(期待値)は、0.852、
卵生か胎生かで分類した場合は0.348、
恒温か変温かで分類した場合は0.505という結果になりました。
これらは、質問によるデータの分岐後、どれくらいデータがばらついているのかを示しています。
図を見てわかる通り、平均情報量の平均(期待値)が最も大きくなった「①草食か肉食か」では、鳥類・哺乳類・爬虫類のデータが散らばっているのに対し、
最も小さくなった「②卵生か胎生か」では、データにまとまりがあることがわかります。
5.各変数を質問としたときの情報利得を計算する。
どの質問を分岐に使ったら良いのかを判断するにあたって「情報利得」という概念があります。
「情報利得」は、ある質問をしてデータを分割した結果、どれくらいエントロピーが減少したかを表す指標です。
元々の平均情報量から、質問によるデータ分割後の平均情報量を引いた値で表されます。
この値が大きければ大きいほど、より有益な質問であると言えます。
3.で求めた全体のエントロピーから、4.で求めたデータ分割後のエントロピーを引き、情報利得を求めます。
①草食か肉食か
②卵生か胎生か
③恒温か変温か
求めた結果、②の情報利得が大きいため、この質問が最も有益であると言えます。
6.情報利得が最も大きい質問を選択し、分割後のデータを新たな集合とみなし、操作を繰り返す。
以下のように、計算した情報利得が最も大きな質問を選択し、それをノードにし、分割後のデータを新たな集合とし、1〜6の操作を繰り返します。
最終的に、以下のような決定木が出来上がります。
この結果を見てわかる通り、食性、発生形態、体温の3種類の質問が存在していたにも関わらず、
発生形態と、体温の2種類しか使われていないことがわかります。
このように、学習の過程で、余分な質問を削除し、最低限の質問で、分類することができます。
まとめ
決定木について、「ID3」というアルゴリズムについて紹介しました。
決定木の最も基本的なアルゴリズムで、このアルゴリズムを改良した「C4.5」アルゴリズムや、「CART」、「CHAID」等あります。
決定木を使用する際は、他のアルゴリズムも確認して見てください。
参考文献














